Rôle du post-traitements
L'introduction de techniques de post-traitement dans les jeux vidéo a profondément transformé l'expérience de jeu, en offrant des améliorations significatives en termes de qualité visuelle, d'immersion et d'esthétique. Le post-traitement, également connu sous le nom de "rendu d'image en post-production", désigne l'ensemble des effets visuels appliqués à une image ou une séquence d'images après leur rendu initial, généralement dans le but d'améliorer leur apparence globale. Dans le contexte des jeux vidéo, le post-traitement intervient après que les éléments 3D ont été rendus en temps réel par le processeur graphique.
L'introduction du post-traitement dans les jeux vidéo s'inscrit dans une quête constante de réalisme visuel et d'immersion accrue des joueurs. En permettant l'application d'effets visuels complexes et réalistes en temps réel, le post-traitement contribue à créer des mondes virtuels plus immersifs et engageants. Les développeurs de jeux vidéo ont recours à une variété d'effets de post-traitement pour améliorer la qualité graphique de leurs jeux, notamment :
Amélioration des effets de lumière et d'ombre : Les techniques de post-traitement permettent de simuler des effets lumineux avancés, tels que l'éblouissement, les reflets, les ombres douces, et les jeux d'ombres et de lumières dynamiques. Ces effets contribuent à créer des environnements plus réalistes et immersifs.
- Effets atmosphériques : Le post-traitement est utilisé pour simuler des phénomènes atmosphériques tels que le brouillard, la brume, la pluie, la neige et le feu, ce qui ajoute de la profondeur et du réalisme aux environnements de jeu.
- Filtrage et anti-aliasing : Les techniques de post-traitement permettent de réduire les artefacts visuels indésirables tels que les bords crénelés et le crénelage, en appliquant des filtres et des techniques d'anti-aliasing pour lisser les contours des objets et améliorer la netteté de l'image.
- Effets de particules et de fluides : Le post-traitement est utilisé pour simuler des effets de particules et de fluides tels que la fumée, le feu, l'eau et les explosions, ce qui ajoute du dynamisme et du réalisme aux scènes d'action.
- Effets de post-traitement artistiques : En plus des effets de post-traitement destinés à améliorer la qualité visuelle, certains jeux utilisent des techniques de post-traitement artistiques pour créer des styles visuels uniques et distinctifs, tels que des effets de dessin animé, de bande dessinée ou de peinture.
En résumé, l'introduction du post-traitement dans les jeux vidéo a ouvert de nouvelles possibilités créatives pour les développeurs, en leur permettant d'améliorer la qualité visuelle et l'immersion des jeux grâce à une variété d'effets visuels réalistes et artistiques. Ces techniques de post-traitement jouent un rôle crucial dans la création de mondes virtuels captivants et inoubliables pour les joueurs du monde entier.
Exemple de post-traitement en jeux vidéo (projet perso) :








Principe du G-Buffer
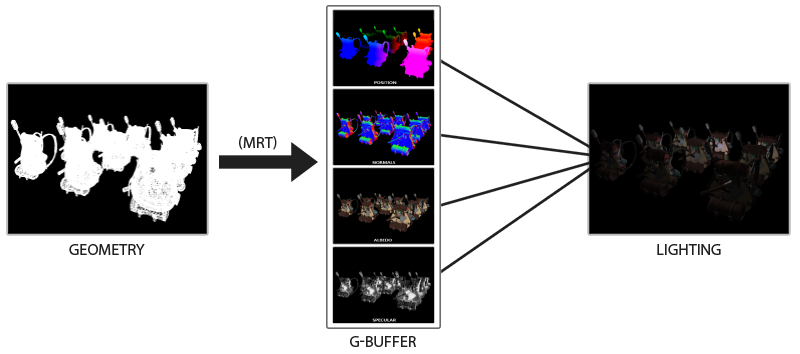
Le principe d’un g-buffer, est de rendre directement dans des frames buffers différents, les données utiliser par un algorithme de rendu pour pouvoir gagner en performance sur l’algorithme notamment car pendant le rendu d’un objet, il n’est pas garanti que le pixel calculer ne soit pas réécrit par celui d’un autre objet plus proche de la camera.
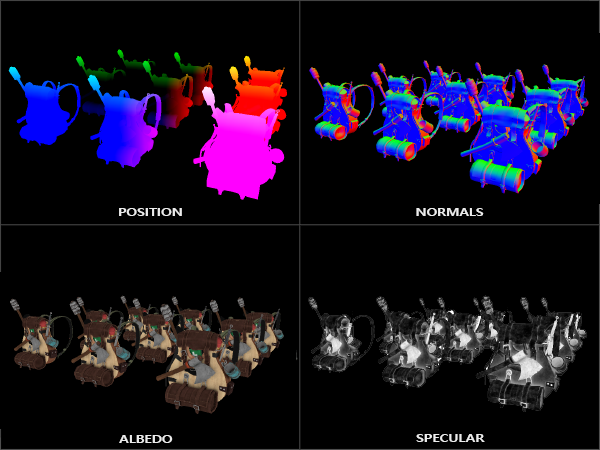
La plus part du temps, ont va exporter les informations suivantes :
- L’albedo : qui correspond à la scène texturer mais sans effet
- Le depth buffer : pour reconstituer les positions 3d
- Les positions du repère : pour retrouver
- Les normals : pour avoir le relief de la scène en face de la camera
- Les coordonées de texture, les tangents, … ou autres, au besoin
Le principe est donc de faire un post-traitement avec les données ainsi calculer, qui permet de gagner beaucoup de performance. Avec une méthode standard il faudrait calculer l’espace utiliser par le fragment shader pour rendre un objet : NxM multiplier par le coût de rendu de chaque pixel avec le fragment shader. Et cela pour chaque objet ce qui implique que des pixel sont calculer en double sans parler du coût de transferts des données vers le gpu et le fragment shader pour pouvoir les calculés, le coût final est donc exponentiel. Alors que, grâce au post-traitement on connaît déjà le temps de rendu et la taille minimal : celle de l’écran avec le même coût, ont n’envoie qu’une seul fois l’information, et le coût est constant. Cela permet par exemple de faire du deffered lighting (number illimitée de lumière), du Hight Dynamic Range, du Screen Space Ambient Occlusion, …. etc etc :)
Principe du HDR (Hight Dynamic Range)
Les valeurs de luminosité et de couleur par défaut sont bloquées entre 0,0 et 1,0 lorsqu'elles sont stockées dans un tampon d’image notamment par ce que un écrans ne peux pas représenter les informations en dehors de cette plage. Cette première déclaration en apparence innocente nous a amenés à toujours spécifier des valeurs de lumière et de couleur quelque part dans cette gamme en essayant de les faire entrer dans la scène. Cela fonctionne et donne des résultats décents, mais que se passe-t-il si nous marchons dans une zone spécifiquement lumineuse avec de multiples sources de lumière lumineuse qui, comme une somme totale de plus de 1,0 ? La réponse est que tous les fragments qui ont une luminosité ou une somme de couleur sur 1,0 sont bloqués à 1,0 ce qui n'est pas joli à regarder et des zone de couleurs très claire ce forme.
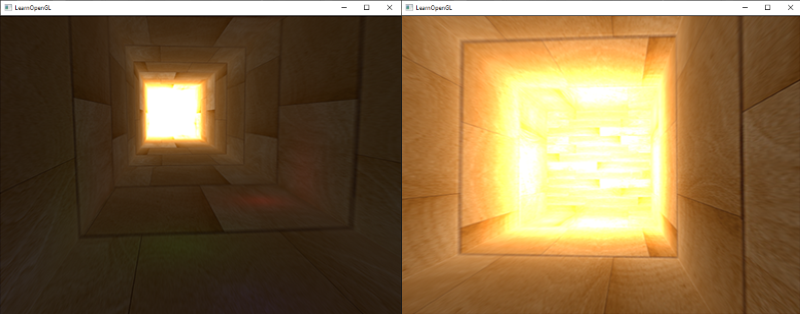
Une solution à ce problème est de réduire la force des sources lumineuses et de s'assurer qu'aucune zone de fragments dans votre scène ne soit plus brillante que 1,0 et inférieur à zéro.Ce n'est pas une bonne solution car cela vous oblige à utiliser des paramètres d'éclairage irréalistes. Une meilleure approche consiste à permettre aux valeurs de couleur de dépasser temporairement 1,0 et de les transformer à la plage originale de 0,0 et 1,0 comme étape finale, mais sans perdre de détails. On calcule alors les extremums de l’image pour normaliser toute l’image
Principe du rendue différé
La façon dont nous faisions l'éclairage jusqu'à présent était de rendre un objet, le lumière selon toutes les sources de lumière dans une scène, puis rendre l'objet suivant, et ainsi de suite pour chaque objet dans la scène. Bien que tout à fait facile à comprendre et à mettre en œuvre, il est également assez lourd en terme de performance : chaque objet rendu doit itérer sur chaque source de lumière pour chaque fragment rendu qui devient exponentiel en fonction du nombre de sources de lumière ! Bien qu’il existe des méthode pour limiter le nombre de lumière utiliser pour rendre un objects pour gagner en performance, cela ne donne pas nécessairement un rendu qui correspond à l’effet voulue, par exemple comme afficher un objet qui représentent une carte entière et l’illuminer avec beacoup de sources de lumière sans trop perdre en performance ?
Le deffered lighting essaie de surmonter ces questions qui modifie drastiquement la façon dont nous rendons des objets. Cela nous donne plusieurs nouvelles options pour optimiser de façon significative les scènes avec un grand nombre de lumières, ce qui nous permet de rendre des centaines voire des milliers de lumières avec un framerate acceptable.
Principe du Screen Space Ambient Occlusion
Le principe de cette algorithme est de calculer un coefficient d’ombrage en fonction de la différence de profondeur avec les pixel adjacent, il existe donc plusieurs méthode afin d’améliorer un des aspects de la méthodes exposée ici, tel-que des erreurs d’approximations, une meilleurs gestions du bruit, de meilleurs performances, … etc. Cette algorithme est effectuer, en post-processing, avec un G-buffer composer de l’albedo (la scene) et du z-buffer (le champ de profondeur)

Le premier problème rencontrer est situer sur le depth-buffer, en effet, à cause de la matrice de projection la profondeur n’est pas linéaire, et de plus de la valeurs contenue dans le depth sont normaliser entre 0 et 1 sur le gpu. Il faut donc recalculer la valeur du depth avec la formule suivante :
- (near*z)/(far-z*(far-near))
- avec near la valeur du plan near de la camera
- idem pour far
- et z la valeur actuel du depth-buffer
Le reste de l’algorithme est une approximation, on va venir calculer la valeurs des depth-buffer à l’intérieur d’un cercle autour du pixel analyser (qui peuvent être interpoler), et faire la moyenne de celle-ci. C’est donc une convolution avec un kernel de grande taille appliquer non pas sur les pixel adjacent brute mais sur les valeurs des sous-pixel interpoler et ont retourne une moyenne pondéré. La plus part des optimisation consiste à faire une approximation de cette convolution en ne calculant pas toutes les valeurs et en appliquant un floutage après.