Principe du G-Buffer
Le principe d’un g-buffer, est de rendre directement dans des frames buffers différents, les données utiliser par un algorithme de rendu pour pouvoir gagner en performance sur l’algorithme notamment car pendant le rendu d’un objet, il n’est pas garanti que le pixel calculer ne soit pas réécrit par celui d’un autre objet plus proche de la camera.
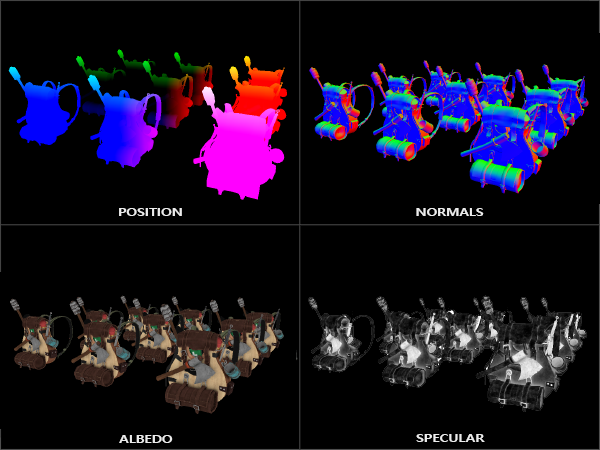
La plus part du temps, ont va exporter les informations suivantes :
- L’albedo : qui correspond à la scène texturer mais sans effet
- Le depth buffer : pour reconstituer les positions 3d
- Les positions du repère : pour retrouver
- Les normals : pour avoir le relief de la scène en face de la camera
- Les coordonées de texture, les tangents, … ou autres, au besoin
Le principe est donc de faire un post-traitement avec les données ainsi calculer, qui permet de gagner beaucoup de performance. Avec une méthode standard il faudrait calculer l’espace utiliser par le fragment shader pour rendre un objet : NxM multiplier par le coût de rendu de chaque pixel avec le fragment shader. Et cela pour chaque objet ce qui implique que des pixel sont calculer en double sans parler du coût de transferts des données vers le gpu et le fragment shader pour pouvoir les calculés, le coût final est donc exponentiel. Alors que, grâce au post-traitement on connaît déjà le temps de rendu et la taille minimal : celle de l’écran avec le même coût, ont n’envoie qu’une seul fois l’information, et le coût est constant. Cela permet par exemple de faire du deffered lighting (number illimitée de lumière), du Hight Dynamic Range, du Screen Space Ambient Occlusion, …. etc etc :)