Une déformation de l'image est toujours present et cela est du a la lentille, et doit être traitée avant tout autre analyse, en particulier si l'on souhait estimer une position. La déformation provoque une détection incorrecte, et endommage la position des pixels, elle a un impact sur l'estimation de la position réelle. Un modèle de non-distorsion de l'objectif doit être appliqué et être le même pour les paramètres intrinsèques de la matrice de la caméra

Modele de distortion
Je propose le modèle de distorsion de lentille suivant, qui est obtenu en ajoutant des coefficients de distorsion tangentielle au modèle de distorsion radiale, une distorsion optionnelle à prisme mince peut également être envisagée. La fonction ci-dessus
où
Chaque partie de l'équation est expliquée ci-dessus :
- Distorsion radiale : La distorsion radiale se produit lorsque les rayons lumineux se courbent plus près des bords d'une lentille qu'ils ne le font en son centre optique. Plus la lentille est petite, plus la distorsion est importante. Les coefficients de distorsion radiale modélisent ce type de distorsion comme une transformation 2D
- Distorsion tangentielle : La distorsion tangentielle corrige les inclinaisons du plan de l'image après une distorsion radiale. Les coefficients de distorsion tangentielle modélisent ce type de distorsion sous la forme d'une transformation 2D
- Distorsion du prisme : La distorsion à prisme mince est due à une légère inclinaison de la lentille ou du réseau de capteurs d'images et provoque également une distorsion radiale et tangentielle supplémentaire. Ce type de déformation n'est généralement pas pris en compte, mais nous l'avons également examiné.
Model d'estimation
class CameraModel(nn.Module): def __init__(self, e=0.1): super(CameraModel, self).__init__() self.K = torch.nn.Parameter(torch.rand(3, dtype=torch.float32)*e) self.P = torch.nn.Parameter(torch.rand(2, dtype=torch.float32)*e) self.S = torch.nn.Parameter(torch.rand(4, dtype=torch.float32)*e) self.fc = torch.nn.Linear(4*2, 2) def radial(self, r, xy): R = torch.stack([r, r**2, r**3], dim=1) K = self.K.repeat(len(r), 1) return xy * torch.sum(K * R, dim=1).unsqueeze(1) def tangential(self, r, xy): P = self.P.unsqueeze(0).repeat(len(xy), 1) px = torch.prod(xy, dim=1).unsqueeze(1) t1 = 2*P*px t2 = P.flip(1)*(r.unsqueeze(1)+xy**2) return t1 + t2 def prismatic(self, r, xy): s1, s2, s3, s4 = self.S S1 = self.S[0] * r + self.S[1] * r**2 S2 = self.S[2] * r + self.S[3] * r**2 P = torch.stack([S1,S2], dim=1) return P def forward(self, xy): r = torch.sum(xy**2, dim=1) R = self.radial(r, xy).to(device=xy.device) T = self.tangential(r, xy).to(device=xy.device) P = self.prismatic(r, xy).to(device=xy.device) return xy + R + T + P def forward_numpy(self, mapx, mapy): ax = mapx.reshape(np.prod(mapx.shape)) ay = mapy.reshape(np.prod(mapy.shape)) xy = np.vstack([ax, ay]).T xy = torch.tensor(xy, dtype=torch.float32).cuda() xy = self.forward(xy) xy = xy.cpu().detach().numpy() ax = xy[:,0].reshape(mapx.shape) ay = xy[:,1].reshape(mapy.shape) return ax, ay
Estimation OpenCV
Pour annuler une image déformée, il faut évaluer le mappage inverse
import numpy as np import cv2 chessboard_shape = (9,6) criteria = (cv2.TERM_CRITERIA_EPS + cv2.TERM_CRITERIA_MAX_ITER, 30, 0.001) objp = np.zeros((chessboard_shape[0] * chessboard_shape[1], 3), np.float32) objp[:,:2] = np.mgrid[0:chessboard_shape[0],0:chessboard_shape[1]].T.reshape(-1,2) images = glob.glob('../data/calibration/chessboard/*.jpg') objpoints = [] # 3d point in real world space imgpoints = [] # 2d points in image plane. print('finding chesboard parameters : ') for i in tqdm(images): image = cv2.imread(i) gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY) ret, corners = cv2.findChessboardCorners(cv2.cvtColor(image,cv2.COLOR_BGR2GRAY), chessboard_shape, None) if ret == True: objpoints.append(objp) corners2 = cv2.cornerSubPix(gray, corners, (11,11), (-1,-1), criteria) imgpoints.append(corners2) print('computing calibration ... ') h, w = image.shape[:2] calibration = cv2.calibrateCamera( objpoints, imgpoints, gray.shape[::-1], None, None, flags = cv2.CALIB_FIX_INTRINSIC + cv2.CALIB_THIN_PRISM_MODEL ) ret, mtx, dist, rvecs, tvecs = calibration cameramtx, roi = cv2.getOptimalNewCameraMatrix(mtx, dist, (w,h), 1, (w,h)) np.save('../result/mtx.npy', mtx) np.save('../result/dist.npy', dist) np.save('../result/cameramtx.npy', cameramtx)
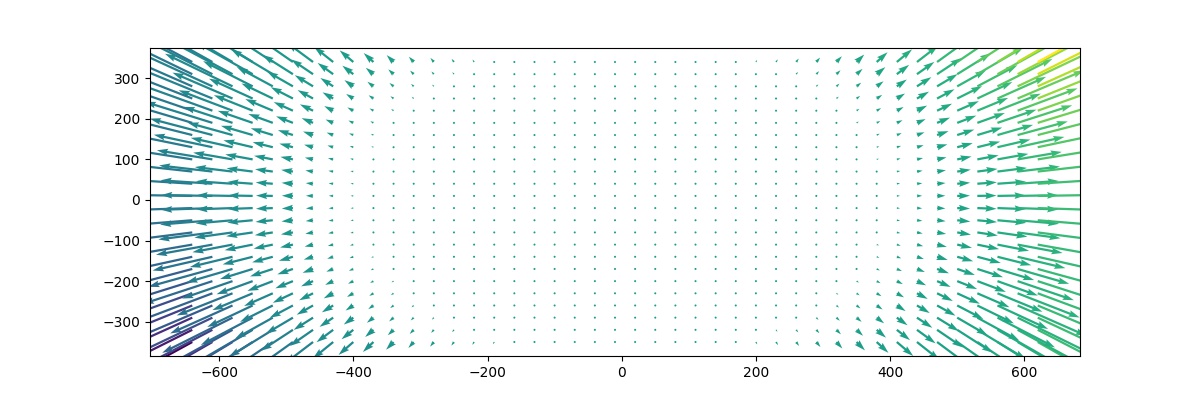
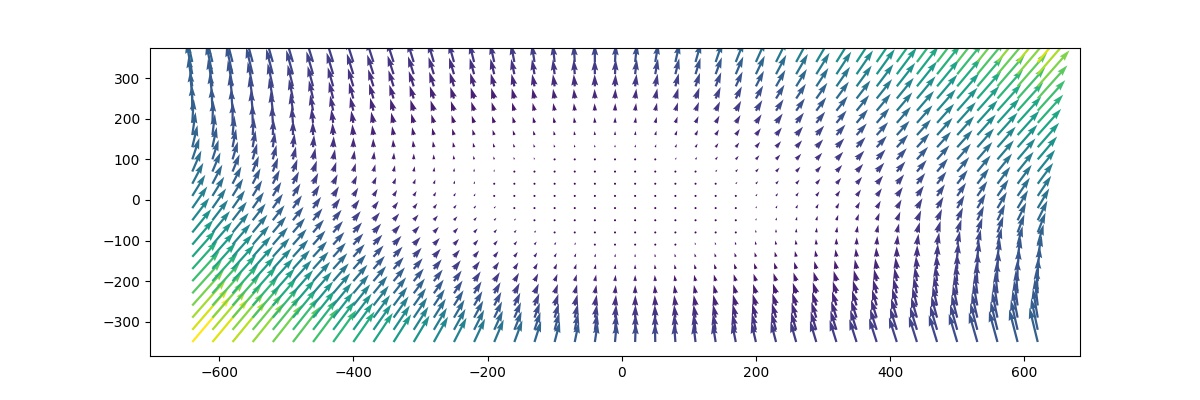
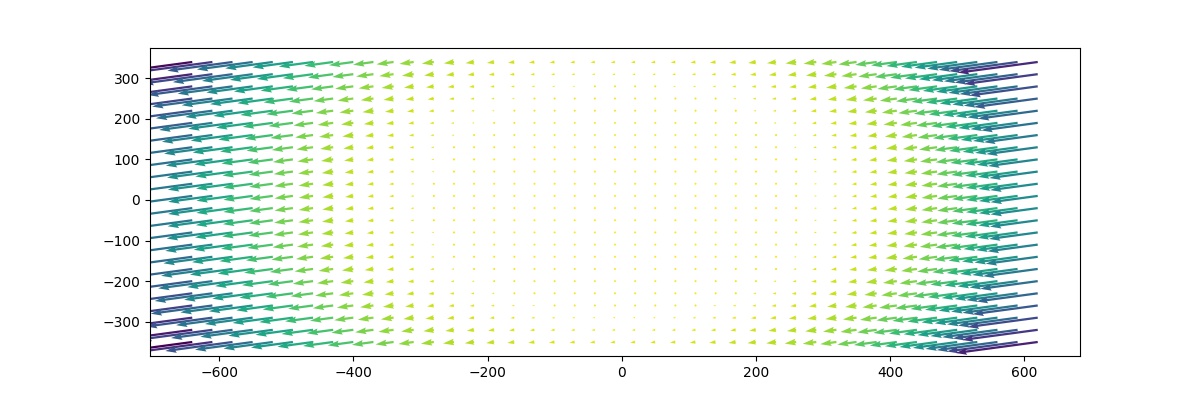
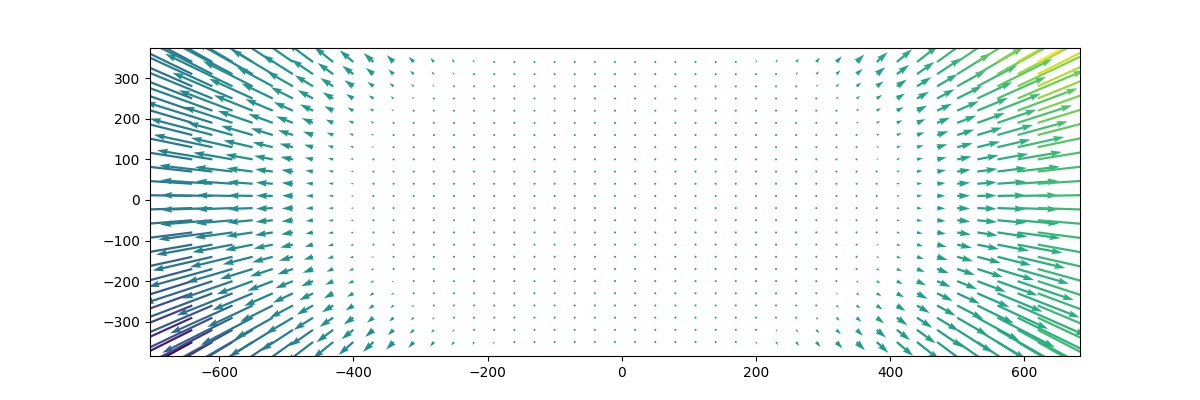
Resulstat
La calibration est estimée avec la calibration de la caméra opencv en utilisant 77 images d'échiquier à différents angles et distances du capteur. Nous pouvons trouver les chiffres de correction
