En géométrie, une enveloppe convexe (convex hull) est le polygone qui contient le plus petit nombre de points d’un ensemble finit, permettant de contenir l’ensemble de départ, cela correspond donc a la limite spatiale de cette ensemble. Dans cette article, nous resterons dans le domaine 2d pour simplifier les calcules et la visualisation. Pour visualisée l’enveloppe convexe on peu imaginer un élastique tendu autour du sous-ensemble (ou dans le cas 3d un emballage de bonbon  ) :
) :
Il existe différents algorithme pour construire une enveloppe convexe que nous allons voir ici, plus ou moins facile et performant en fonction de la répartition spatial des points dans l'ensemble. Dans tout les cas nous auront besoin de connaître le signe de l'angle entre 3 points, pour le quel nous définition une première fonction :
def CCW(p1, p2, p3): return (p3[1]-p1[1])*(p2[0]-p1[0]) >= (p2[1]-p1[1])*(p3[0]-p1[0])
Ainsi que quelques fonctions "outils" supplémentaire, comme récupérer l'indice du point le plus en bas a gauche et une fonction de trie spécifique (quick sort custom pour un temps raisonnable) :
def get_lower_left_index(P): j = 0; for i in range(1,P.shape[0]): if P[i][1] < P[j][1]: j = i; elif P[i][1] == P[j][1]: if P[i][0] < P[j][0]: j = i; return j; def partition(X, predicator,low,high): i = low-1 pivot = X[high] for j in range(low , high): if predicator(pivot, X[j]): i = i+1 X[i],X[j] = X[j],X[i] X[i+1],X[high] = X[high],X[i+1] return i+1 def qsort(X, predicator, low, high): if low < high: pi = partition(X, predicator, low, high) qsort(X, predicator, low, pi-1) qsort(X, predicator, pi+1, high)
Algorithme de Jarvis
L'algorithme de Jarvis aussi connue sous le nom de GiftWarping est en un sens le plus simple. Sa complexité dépend de la sortie du problème, ici du nombre de sommets de l'enveloppe convexe. On commence par récupérer l'indice du point le plus en bas a gauche, qui appartient par nature a l'enveloppe convexe. Ensuite on place cette élément a la fin des points a analyser, ce qui nous permettras de tester que l'on a parcourue tout nos point (fin de l'algo). Finalement a chaque itération on recupere le prochain point le poins a droite (qui ne tourne pas vers l'intérieur) entre le point précédent, le point courent et tout les autres .... et ainsi de suite jusqu'a rejoindre le point en bas a gauche (donc le dernier de la liste) :
def GiftWrapping(S): ll = get_lower_left_index(S) hull = [S[ll]] # on deplace [ll] au debut pour garantir qu'il appartient au hull end = S[0] S[0] = S[ll] S[ll] = end i = 1 while i != 0: i = 1 # on cherche le prochain point le plus a droite # donc qui ne troune pas vers l'interieur # si 'aucun' -> i=0 -> fermeture for j in range(S.shape[0]): if not CCW(S[j], hull[-1], S[i]): i = j hull.append(S[i]) del hull[-1] return np.array(hull)
Algorithme de Graham
L'algorithme de Graham ce décompose en deux partie, une première partie qui consiste a trouver le polygone (concave) associer a l'ensemble de départ, avec un balayage, grossomodo un trie par angle polaire (point gourmand en terme de complexité), utilisant CCW et le qsort précédemment défini nous pouvons l'écrire de cette façon :
from functools import partial def GrahamScan(P): ll = get_lower_left_index(P) reference = P[ll] P = np.delete(P, ll, 0).tolist() # sorting by angle to the reference predicate = partial(CCW, reference) qsort(P, predicate, 0, len(P)-1) return np.vstack([P, reference])
 Exemple de balayage de Graham sur un ensemble losange
Exemple de balayage de Graham sur un ensemble losange
La deuxième partie consiste a jouter les points au fur et a mesure, et lorsque l'on s'apperçois que l'on tourne a droite alors on ne respecte plus la propriété convexe, et on supprime donc les éléments précèdent jusqu'a ce que l'on redevienne convexe, on écrira alors la fonction :
def GrahamHull(P): P = GrahamScan(P) hull = [P[0], P[1]] for i in range(P.shape[0]): while not CCW(hull[-1], hull[-2], P[i]): hull.pop() hull.append(P[i]) return np.array(hull)
Algorithme de Kirkpatrick–Seidel
Kirkpatrick-Seidel (KS) est un algorithme géométrique permettant de résoudre le problème de la paire la plus proche dans un plan à deux dimensions. Le problème de la paire la plus proche consiste à trouver les deux points les plus proches dans un ensemble de points. Ce problème a de nombreuses applications en géométrie informatique, en traitement d'images et en reconnaissance de formes. Cette algorithme est un peu particulier, puisqu'il ne garantie pas forcement que la solution trouver soit convexe, mais néanmoins la solution sans rapproche le plus possible. De plus cette algorithme decompose le probleme en 4, partie haut, bas puis subdivision en gauche et droit :
def upper_hull(points): lower = min(points) upper = max(points) points = {lower, upper} | {p for p in points if lower[0] < p[0] < upper[0]} return connect(lower, upper, points) def flipped(points): return [(-point[0], -point[1]) for point in points] def KirkpatrickSeidel(points): points = [(i[0], i[1]) for i in points] upper = upper_hull(points) lower = flipped(upper_hull(flipped(points))) if upper[-1] == lower[0]: del upper[-1] if upper[0] == lower[-1]: del lower[-1] return np.array(upper + lower)
L'algorithme KS fonctionne comme suit :
- Trier les points de l'ensemble d'entrée en fonction de leurs coordonnées x. Cette opération peut être effectuée à l'aide d'un algorithme de tri basé sur la comparaison, tel que le tri sélectif ou le tri par fusion.
- Diviser l'ensemble d'entrée en deux ensembles de points de taille égale. Pour ce faire, il convient de trouver le point médian et de diviser l'ensemble en deux ensembles selon que les points se trouvent à gauche ou à droite de la médiane.
- Appliquer récursivement les étapes 2 et 3 à chacun des deux sous-ensembles jusqu'à ce que les sous-ensembles ne contiennent qu'un ou deux points. Si un sous-ensemble ne contient qu'un seul point, il s'agit de la paire la plus proche. Si un sous-ensemble contient deux points, la paire la plus proche est soit les deux points du sous-ensemble, soit la paire la plus proche de l'autre sous-ensemble.
- Trouvez la paire la plus proche entre les deux sous-ensembles. Pour ce faire, créez une bande verticale de points autour de la ligne médiane et ne prenez en compte que les points de la bande qui sont plus proches de la ligne médiane que la distance d de la paire la plus proche trouvée aux étapes 2 et 3. Cette méthode réduit le nombre de points à prendre en compte et peut être réalisée en temps linéaire.
def quickselect(ls, index, lo=0, hi=None, depth=0): if hi is None: hi = len(ls)-1 if lo == hi: return ls[lo] pivot = randint(lo, hi) ls = list(ls) ls[lo], ls[pivot] = ls[pivot], ls[lo] cur = lo for run in range(lo+1, hi+1): if ls[run] < ls[lo]: cur += 1 ls[cur], ls[run] = ls[run], ls[cur] ls[cur], ls[lo] = ls[lo], ls[cur] if index < cur: return quickselect(ls, index, lo, cur-1, depth+1) elif index > cur: return quickselect(ls, index, cur+1, hi, depth+1) else: return ls[cur] def bridge(points, vertical_line): candidates = set() if len(points) == 2: return tuple(sorted(points)) pairs = [] modify_s = set(points) while len(modify_s) >= 2: pairs += [tuple(sorted([modify_s.pop(), modify_s.pop()]))] if len(modify_s) == 1: candidates.add(modify_s.pop()) slopes = [] for pi, pj in pairs[:]: if pi[0] == pj[0]: pairs.remove((pi, pj)) candidates.add(pi if pi[1] > pj[1] else pj) else: slopes += [(pi[1]-pj[1])/(pi[0]-pj[0])] median_index = len(slopes)//2 - (1 if len(slopes) % 2 == 0 else 0) median_slope = quickselect(slopes, median_index) small = {pairs[i] for i, slope in enumerate(slopes) if slope < median_slope} equal = {pairs[i] for i, slope in enumerate(slopes) if slope == median_slope} large = {pairs[i] for i, slope in enumerate(slopes) if slope > median_slope} max_slope = max(point[1]-median_slope*point[0] for point in points) max_set = [point for point in points if point[1]-median_slope*point[0] == max_slope] left = min(max_set) right = max(max_set) if left[0] <= vertical_line and right[0] > vertical_line: return (left, right) if right[0] <= vertical_line: candidates |= {point for _, point in large | equal} candidates |= {point for pair in small for point in pair} if left[0] > vertical_line: candidates |= {point for point, _ in small | equal} candidates |= {point for pair in large for point in pair} return bridge(candidates, vertical_line) def connect(lower, upper, points): if lower == upper: return [lower] max_left = quickselect(points, len(points)//2-1) min_right = quickselect(points, len(points)//2) left, right = bridge(points, (max_left[0] + min_right[0])/2) points_left = {left} | {point for point in points if point[0] < left[0]} points_right = {right} | {point for point in points if point[0] > right[0]} return connect(lower, left, points_left) + connect(right, upper, points_right)
Analyse du temps d'execution
Pour tester nous avons besoin de quelques petites fonctions pour générer des ensembles suivant certaine forme, comme des rectangle, losange ou cercle :
def random_set_limit(N, s, pred): X = [None] * N for i in range(N): while X[i] is None or pred(X[i]) > 0.0: X[i] = np.random.random(2)*2-1 return np.int32(np.array(X)*s) def random_set_square(N,s=1000): return np.int32((np.random.random((N,2))-0.5) * s) def random_set_circle(N, s=1000): return random_set_limit(N, s, lambda p : np.sum(p**2)-1) def random_set_octagone(N, s=1000): return random_set_limit(N, s, lambda p : np.sum(abs(p))-np.sqrt(2)) def random_set_lozenge(N, s=1000, angle=45): X = random_set_square(N,s) theta = np.radians(angle) c, s = np.cos(theta), np.sin(theta) R = np.array(((c, -s), (s, c))) return np.matmul(R,X.transpose()).transpose()
Avec tout cela nous pouvons analyser leurs temps d'execution en fonction du nombre de point et de la forme de l'enveloppe convexe, ce qui nous donne les trois figures suivantes :
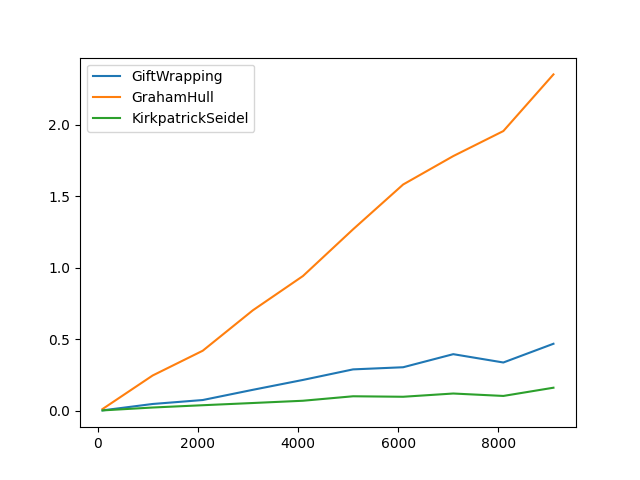
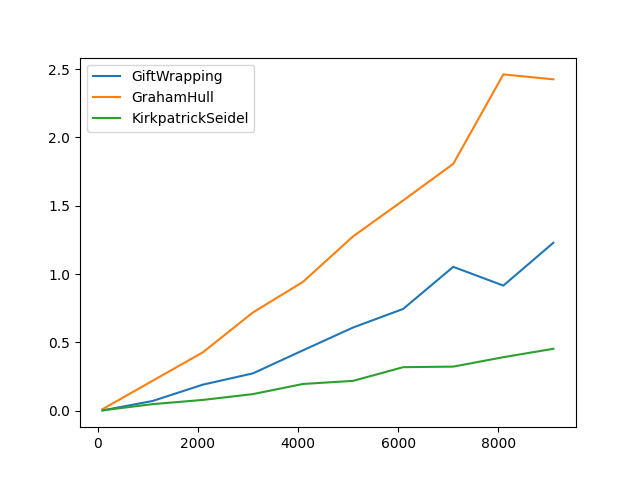
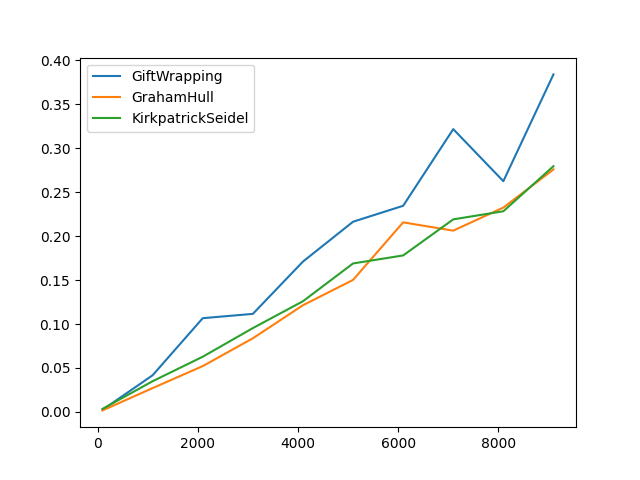
On peu voir effectivement que l'algorithme de Graham est le moins efficient, partielement due a la fonction de trie (qsort