Introduction
L’analyse spectrale des graphes repose sur l’étude des valeurs propres et vecteurs propres des matrices associées au graphe, notamment la matrice d’adjacence $A$, la matrice de degré $D$, et la matrice de Laplacien $L=D−A$. Ces matrices capturent les différentes facettes de la structure du graphe et permettent d’en extraire des informations profondes sur sa connectivité, sa bipartition ou encore ses communautés.
Rappel
La matrice d’adjacence \(A \in \mathbb{R}^{n \times n}\) est définie par
\[
A_{ij} =
\begin{cases}
1 & \text{si } \{i,j\} \in E, \\
0 & \text{sinon.}
\end{cases}
\]
Elle encode entièrement qui est connecté à qui dans le graphe.
Quelques faits clés (sans démonstration ici) :
- Les valeurs propres de \(A\) décrivent la structure globale du graphe, par exemple la présence de communautés ou la régularité du graphe.
- Pour un graphe non orienté, \(L\) possède toujours une valeur propre égale à \(0\). Le nombre de valeurs propres nulles est exactement le nombre de composantes connexes du graphe.
- La plus petite valeur propre strictement positive de \(L\) (souvent notée \(\lambda_2\), la « Fiedler value ») mesure en un certain sens la qualité de la connexité : plus \(\lambda_2\) est grande, plus le graphe est « bien connecté ».
- Pour un graphe biparti, comme évoqué plus haut, le spectre de \(A\) est symétrique : si \(\lambda\) est valeur propre, \(-\lambda\) en est aussi une. Cela permet de reconnaître la bipartité par des critères purement algébriques.
Un exemple typique d’application est le clustering spectral : on diagonalise (ou on approxime) la matrice \(L_{\text{norm}}\), on regarde quelques vecteurs propres associés aux plus petites valeurs propres, puis on applique un algorithme de clustering classique (comme \(k\)-means) dans cet espace réduit.
En pratique, on évite de calculer toutes les valeurs propres : on utilise des méthodes itératives (power iteration, Lanczos) adaptées aux matrices creuses.
Reference interessante : math.uchicago
Matrice de degré et Laplacien
On définit d’abord la matrice de degré \(D\) comme une matrice diagonale où : $D_{ii} = \deg(x_i), \quad D_{ij} = 0 \text{ si } i \ne j. $ Dit autrement :
\[
D_{ii} = \deg(i) = \sum_{j=1}^n A_{ij}.
\]
Pour un graphe non orienté simple (sans boucle), la matrice de Laplacien est donnée par : $L = D - A$. Cette matrice est symétrique, définie positive, et joue pour les graphes un rôle analogue à l’opérateur laplacien en analyse (diffusion, chaleur, etc.).
- Matrice d’adjacence $A$
- Elle encode la structure de connexion du graphe.
- Son spectre (ensemble de valeurs propres) reflète la présence de motifs ou de sous-structures.
- Matrice de degré $D$
- Elle mesure la densité locale de chaque nœud
- Matrice de Laplacien $L$
- Elle compare la valeur en un sommet à la moyenne de ses voisins (diffusion, chaleur, lissage).
- Si un sommet est très différent de ses voisins, la valeur associee sera grande
- Utilisee en analyse d’image : https://homepages.inf.ed.ac.uk/rbf/HIPR2/log.htm
- Dit autrement c’est une derivee spatial
On peut aussi définir un laplacien normalisé (utile en clustering spectral) via $L_{\text{norm}} = I - D^{-1/2} A D^{-1/2}$, lorsque tous les degrés sont strictement positifs. Concernant $D^{-1/2}$, c’est très simple puisque $D$ est diagonal. On peu prednre le raccouci suivant :
\[ D = \begin{bmatrix} d_1 & 0 & 0 \\ 0 & d_2 & 0 \\ 0 & 0 & d_3 \end{bmatrix} ; D^{-1/2} = \begin{bmatrix} \frac{1}{\sqrt{d_1}} & 0 & 0 \\ 0 & \frac{1}{\sqrt{d_2}} & 0 \\ 0 & 0 & \frac{1}{\sqrt{d_3}} \end{bmatrix} \]
En python
import numpy as np
A = np.array([
[0, 1, 1],
[1, 0, 0],
[1, 0, 0]
])
deg = A.sum(axis=1)
# laplacien
D = np.diag(deg)
L = D - A
# laplacien normalisé
D_inv_sqrt = np.diag(1/np.sqrt(deg))
I = np.eye(len(A))
L_norm = I - D_inv_sqrt @ A @ D_inv_sqrt
Et si le graph a une boucle
On peut écrire une matrice Laplacienne pour un graphe qui contient des boucles, mais il faut “ajuster” la définition classique pour tenir compte de ces boucles. Une boucle sur un sommet $i$ est un edge qui relie $i$ à lui-même. On note :
\[ (i,i) \in E \]
- Dans la matrice d’adjacence \(A\), une boucle se traduit par \(A_{ii} = 1\) (ou le poids de la boucle si pondérée).
- Dans le calcul du degré pour la diagonale de \(D\), chaque boucle contribue 2 au degré du sommet (i) (en théorie du graphe non orienté) parce qu’elle touche le sommet à la fois à l’entrée et à la sortie.
Matrice Laplacienne avec boucles
Pour un graphe avec boucles, la matrice Laplacienne reste $L = D - A$ avec :
\[ D_{ii} = \text{degré du sommet } i = \text{nombre d’arêtes incidentes, en comptant 2 pour chaque boucle} \]
et
\[ A_{ii} = \text{nombre de boucles sur } i \]
En soit pas de changement c’est juste un rapelle, car $deg(x_i) = deg^+(x_i) + deg^-(x_i) = $. Par definition une boucle compte forcement double dans $D_{ii}$
Exemple concret :
Graphe à 3 sommets avec une boucle sur le sommet 1 et une arête 1–2 :
\[ A = \begin{bmatrix} 1 & 1 & 0 \\ 1 & 0 & 0 \\ 0 & 0 & 0 \end{bmatrix}, \quad D = \begin{bmatrix} 3 & 0 & 0 \\ 0 & 1 & 0 \\ 0 & 0 & 0 \end{bmatrix} \]
Alors :
\[ L = D - A = \begin{bmatrix} 2 & -1 & 0 \\ -1 & 1 & 0 \\ 0 & 0 & 0 \end{bmatrix} \]
Remarquez que le degré du sommet 1 est \(3 = 2 \text{(boucle)} + 1 \text{(arête 1–2)}\).
Conclusion
- Oui, la matrice Laplacienne existe même si le graphe a des boucles.
- Il faut compter correctement les boucles dans le degré (2 par boucle pour un graphe non orienté).
- La matrice reste symétrique pour un graphe non orienté.
Valeurs et vecteurs propres
Petits rapelle pour ceux qui ont oubliés : Comment derterminer les valeurs et vecteurs propres d’une matrice.
On considère une matrice carrée \(M\). Une valeur propre \(\lambda\) et un vecteur propre non nul \(v\) satisfont : $M v = \lambda v$. Autrement dit, $(M - \lambda I)v = 0$. Dit autrement c’est un systeme d’equation polynomial.
Pour trouver les valeurs propres :
- On cherche les \(\lambda\) tels que le système \((M - \lambda I)v = 0\) admette une solution non triviale (autre que \(v = 0\)).
- Cela arrive exactement quand \(\det(M - \lambda I) = 0\).
- On résout donc l’équation caractéristique \(\det(M - \lambda I) = 0\) (polynôme en \(\lambda\)).
- Les racines obtenues sont les valeurs propres.
Pour chaque valeur propre \(\lambda\) :
- On remplace \(\lambda\) dans \(M - \lambda I\).
- On résout le système linéaire \((M - \lambda I)v = 0\).
- Les solutions non nulles \(v\) forment l’espace propre associé à \(\lambda\)
En pratique :
- à la main, on fait cela uniquement pour des petites matrices (2×2, 3×3), pour des exercices etudiants …
- donc pour comprendre et potentielement implementer ces fonctions sur ordinateur …
- globalement on utilisera des fonctions numériques (
numpy.linalg.eig,scipy.linalg.eig, etc.)
Rapelle mathematique vecteur propre et valeurs propres
Considérons la matrice
\[ M = \begin{bmatrix} 2 & 1 \\ 1 & 2 \end{bmatrix}. \]
- On va calculer ses valeurs propres et vecteurs propres.
On cherche donc \(\lambda\) tel que \(\det(M - \lambda I) = 0\).
\[ M - \lambda I = \begin{bmatrix} 2-\lambda & 1 \\ 1 & 2-\lambda \end{bmatrix} \]
Donc
\[ \det(M - \lambda I) = (2-\lambda)(2-\lambda) - 1\cdot 1 = (2-\lambda)^2 - 1. \]
On développe :
\[ (2-\lambda)^2 - 1 = (4 - 4\lambda + \lambda^2) - 1 = \lambda^2 - 4\lambda + 3. \]
Équation caractéristique :
\[ \lambda^2 - 4\lambda + 3 = 0. \]
Calcul du discriminant :
\[ \Delta = b^2 - 4ac \]
\[ \Delta = (-4)^2 - 4 \times 1 \times 3 \]
\[ \Delta = 16 - 12 = 4 \]
Racines :
\[ \lambda = \frac{-b \pm \sqrt{\Delta}}{2a} = \frac{4 \pm \sqrt{4}}{2} = \frac{4 \pm 2}{2} = \{1, 3\} \]
Les valeurs propres sont donc :
\[ \lambda_1 = 1, \quad \lambda_2 = 3. \]
- Vecteur propre pour \(\lambda_1 = 1\)
On résout \((M - I)v = 0\).
\[ M - I = \begin{bmatrix} 2-1 & 1 \\ 1 & 2-1 \end{bmatrix} = \begin{bmatrix} 1 & 1 \\ 1 & 1 \end{bmatrix}. \]
On cherche un vecteur \(v = \begin{bmatrix} x \\ y \end{bmatrix} \neq 0\) tel que :
\[ \begin{bmatrix} 1 & 1 \\ 1 & 1 \end{bmatrix} \begin{bmatrix} x \\ y \end{bmatrix} = \begin{bmatrix} 0 \\ 0 \end{bmatrix}. \]
Cela donne le système :
\[ \begin{cases} x + y = 0 \\ x + y = 0 \end{cases} \Rightarrow y = -x. \]
Un vecteur propre (au choix) est donc :
\[ v_1 = \begin{bmatrix} 1 \\ -1 \end{bmatrix} \]
- Vecteur propre pour \(\lambda_2 = 3\)
On résout \((M - 3I)v = 0\).
\[ M - 3I = \begin{bmatrix} 2-3 & 1 \\ 1 & 2-3 \end{bmatrix} = \begin{bmatrix} -1 & 1 \\ 1 & -1 \end{bmatrix}. \]
On cherche \(v = \begin{bmatrix} x \\ y \end{bmatrix} \neq 0\) tel que :
\[ \begin{bmatrix} -1 & 1 \\ 1 & -1 \end{bmatrix} \begin{bmatrix} x \\ y \end{bmatrix} = \begin{bmatrix} 0 \\ 0 \end{bmatrix}. \]
Système :
\[ \begin{cases} - x + y = 0 \\ x - y = 0 \end{cases} \Rightarrow y = x. \]
Un vecteur propre (au choix) est donc :
\[ v_2 = \begin{bmatrix} 1 \\ 1 \end{bmatrix} \]
\(Lf\) et interprétation
Si \(f : V \to \mathbb{R}\) est une fonction sur les sommets, que l’on voit comme un vecteur \(f \in \mathbb{R}^n\), alors la \(i\)-ème composante de \(Lf\) vaut
\[
(Lf)_i = \deg(i)\, f(i) - \sum_{j \sim i} f(j),
\]
où la somme porte sur les voisins \(j\) de \(i\).
- Si \(f(i)\) est très différent de la moyenne de \(f\) sur les voisins de \(i\), alors \((Lf)_i\) est grand en valeur absolue.
- Si \(f\) est “lisse” sur le graphe (les voisins ont des valeurs proches), alors \(Lf\) est petit.
On peut donc voir \(L\) comme un opérateur qui mesure le désaccord local entre un sommet et ses voisins.
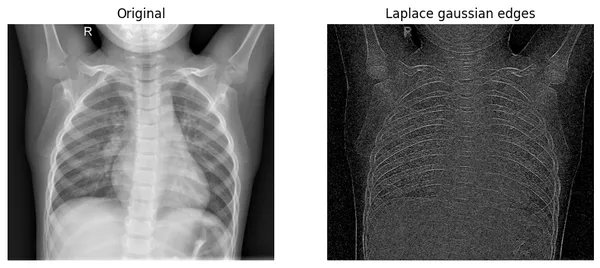
Exemple en analyse d’image
En traitement d’images, on applique souvent le laplacien discret (ou un laplacien de Gauss) sur l’image vue comme une fonction \(f(x,y)\) définie sur la grille de pixels. Cela permet de détecter les contours en mettant en évidence les zones où l’intensité varie brutalement, typiquement via les zéros de la dérivée seconde ou les zéros de croisement du laplacien. On peut aussi combiner le laplacien avec un filtrage préalable (flou gaussien) pour rehausser les contours sans amplifier le bruit.
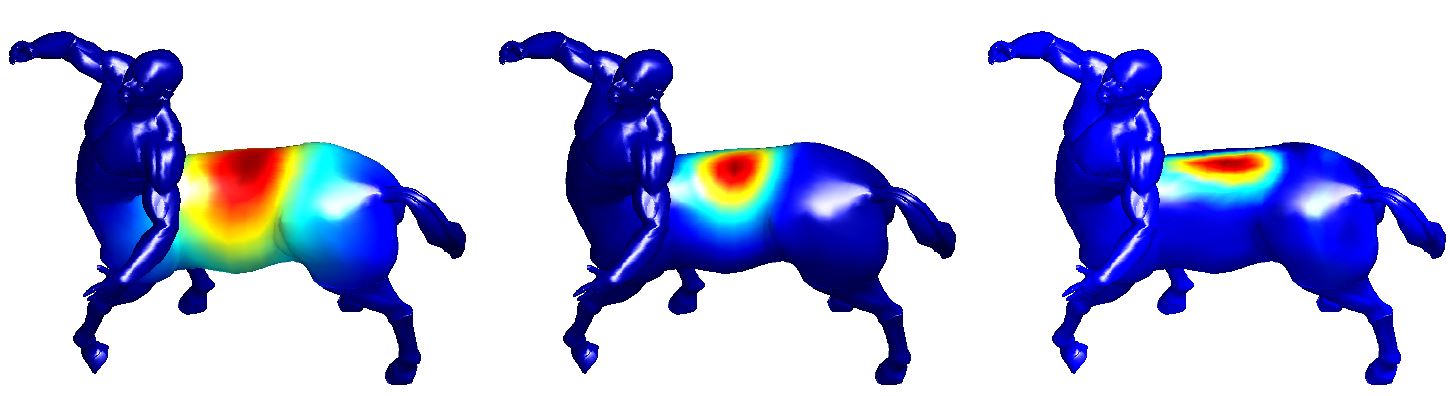
Exemple en analyse de surface
En géométrie différentielle et en analyse de formes 3D, l’analogue continu du laplacien (le Laplacien de Beltrami sur une surface) sert à caractériser la déformation locale : il est lié à la courbure moyenne et aux directions principales de courbure. On l’utilise pour détecter des zones de forte courbure ou de changement de signe de la courbure (points d’inflexion de type Saddle), mais aussi pour la segmentation et la mise en correspondance de formes.
Connexité et valeurs propres
Pour un graphe simple non orienté \(G\) avec Laplacien \(L = D - A\) :
- \(L\) est symétrique et semi‑définie positive : toutes ses valeurs propres sont réelles et \(\lambda_i \ge 0\).
- \(0\) est toujours une valeur propre de \(L\), avec pour vecteur propre associé le vecteur constant \(\mathbf{1} = (1,\dots,1)^\top\).
- Le nombre de valeurs propres nulles de \(L\) est exactement le nombre de composantes connexes de \(G\).
Le fait que \(L\) soit symétrique vient de ce que \(A\) et \(D\) le sont. Pour la semi‑définie positivité, on montre que pour tout \(x \in \mathbb{R}^n\), ce qui force toutes les valeurs propres à être non négatives.
\[ x^\top L x = \frac{1}{2} \sum_{\{i,j\} \in E} (x_i - x_j)^2 \ge 0, \]
La nullité correspond à \(x_i = x_j\) pour tout \(\{i,j\} \in E\) : sur chaque composante connexe, \(x\) doit être constant. Le nombre de degrés de liberté (constantes indépendantes) est donc le nombre de composantes connexes.
Caleur de Fiedler
On note $0 = \lambda_1 \le \lambda_2 \le \dots \le \lambda_n$ les valeurs propres de \(L\), comptées avec multiplicité. La valeur \(\lambda_2\) est appelée valeur de Fiedler, et un vecteur propre associé \(v_2\) est appelé vecteur de Fiedler.
- Si \(\lambda_2 > 0\), le graphe est connexe. Si \(\lambda_2 = 0\), il est déconnecté.
- Plus \(\lambda_2\) est grande, plus le graphe est “bien connecté” : il n’existe pas de coupure de petite capacité qui sépare le graphe en deux gros morceaux.
- Les composantes de \(v_2\) varient doucement et se regroupent souvent en deux blocs (valeurs positives vs négatives), ce qui suggère une partition naturelle du graphe en deux sous‑ensembles.
Fiedler partition
Soit un graphe avec deux communautés faiblement connectées (par quelques arêtes seulement). On calcule \(L\), puis ses deux plus petites valeurs propres. On vérifie que \(\lambda_1 = 0\) et que \(\lambda_2\) est très proche de 0.
- Le vecteur propre \(v_2\) a des composantes positives sur la première communauté, et négatives sur la seconde (ou l’inverse).
- En séparant les sommets selon le signe de \(v_2(i)\), on obtient une coupure de Fiedler, souvent proche de la meilleure coupure possible.
Graphes bipartis
Un graphe non orienté \(G = (V,E)\) est biparti s’il existe une partition de l’ensemble des sommets \(V = U \cup W\) telle que :
- \(U \cap W = \emptyset\),
- chaque arête \(\{i,j\} \in E\) relie un sommet de \(U\) à un sommet de \(W\).
Autrement dit, il n’y a aucune arête entre deux sommets de \(U\), ni entre deux sommets de \(W\).
Théorème (forme bloc de \(A\)) Si \(G\) est biparti avec partition \(V = U \cup W\), alors on peut réordonner les sommets (mettre d’abord ceux de \(U\), puis ceux de \(W\)) de sorte que la matrice d’adjacence \(A\) s’écrive sous la forme bloc \(B\) est la matrice de bi‑adjacence entre \(U\) et \(W\) :
\[ A = \begin{pmatrix} 0 & B \\ B^\top & 0 \end{pmatrix}, \]
Cette écriture reflète exactement le fait qu’il n’y a pas d’arêtes internes dans \(U\) ni dans \(W\) (blocs diagonaux nuls), seulement des arêtes entre les deux parties (blocs \(B\) et \(B^\top\)).
Algorithme pratique pour trouver la bipartition / coloration
En pratique, si le graphe est biparti (ou si l’on veut tester s’il l’est), on peut utiliser un algorithme de type BFS/DFS coloré (que l’on verra plus tard) :
- Entrée : graphe \(G = (V,E)\).
- Sortie : soit une partition \(V = U \cup W\) (graph biparti) soit
None
- Initialiser un tableau
colorde taille \(|V|\) à la valeur-1(couleur inconnue). - Pour chaque composante connexe (pour chaque sommet \(s\) tel que
color[s] = -1) : - fixer
color[s] = 0, mettre \(s\) dans une file (BFS) ou sur une pile (DFS) ; - tant que la file n’est pas vide :
- extraire un sommet \(u\),
- pour chaque voisin \(v\) de \(u\) :
- si
color[v] = -1, posercolor[v] = 1 - color[u](alterner les couleurs), - sinon, si
color[v] = color[u], il existe un cycle impair, donc le graphe n’est pas biparti.
- si
- Si on termine sans conflit, l’ensemble des sommets tels que
color[i] = 0forme \(U\), ceux aveccolor[i] = 1forment \(W\).
En Python (pseudo‑code) :
from collections import deque
def bipartition(adj_list):
n = len(adj_list)
color = [-1] * n
for s in range(n):
if color[s] != -1:
continue
color[s] = 0
queue = deque([s])
while queue:
u = queue.popleft()
for v in adj_list[u]:
if color[v] == -1:
color[v] = 1 - color[u]
queue.append(v)
elif color[v] == color[u]:
return None # non biparti
U = [i for i in range(n) if color[i] == 0]
W = [i for i in range(n) if color[i] == 1]
return U, W
Réordonnancement de la matrice \(A\)
Une fois \(U\) et \(W\) trouvés, on définit une permutation des sommets qui met d’abord \(U\), puis \(W\). Concrètement :
- On construit un vecteur
permqui contient les indices de \(U\) suivis des indices de \(W\). - On applique cette permutation aux lignes et colonnes de \(A\) :
import numpy as np
def reorder_adjacency(A, U, W):
perm = np.array(U + W)
A_perm = A[np.ix_(perm, perm)]
return A_perm, perm
La matrice permutée \(A_{\text{perm}}\) a alors la forme bloc
\[
A_{\text{perm}} =
\begin{pmatrix}
0 & B \\
B^\top & 0
\end{pmatrix}.
\]
Interprétation spectrale
Pour un graphe biparti, le spectre de \(A\) est symétrique par rapport à 0 : si \(\lambda\) est valeur propre de \(A\), alors \(-\lambda\) l’est aussi, avec la même multiplicité.
Idée. Dans la forme bloc :
\[ A = \begin{pmatrix} 0 & B \\ B^\top & 0 \end{pmatrix}, \]
on vérifie que si \((x, y)^T\) est un vecteur propre de valeur propre \(\lambda\), alors \((x, -y)^T\) est vecteur propre de valeur propre \(-\lambda\). D’où la symétrie du spectre.
Extraction des deux parties
On peut utiliser un critère spectral pour retrouver la bipartition :
- On calcule la plus grande valeur propre \(\lambda_{\max}\) de \(A\) et un vecteur propre associé \(v\).
- Pour un graphe biparti connexe, on sait (Perron‑Frobenius adapté) qu’il existe un vecteur propre pour \(-\lambda_{\max}\) qui s’obtient en changeant le signe sur une des deux parties.
- En pratique, on regarde le signe des composantes de \(v\) (ou d’un vecteur propre de \(-\lambda_{\max}\)) :
- indices où \(v_i > 0\) ⇒ première classe,
- indices où \(v_i < 0\) ⇒ seconde classe.
Cela marche bien pour des graphes “fortement” bipartis ou des sous‑graphes bipartis, et peut servir de base à des heuristiques pour trouver de grands sous‑graphes bipartis… La suite peut devenir complexe et surtout hors programme.