La théorie des graphes concerne de nombreux domaines d’application. Leurs objectifs diffèrent, mais le langage utilisé est le même. Les graphes servent à modéliser des ensembles structurés et complexes, avec des applications aussi variées que la modélisation temporelle (en économie ou en automatique) ou la représentation de réseaux (électrique, routier, adduction d’eau, etc.). La théorie des graphes est née en 1736, quand Euler démontra qu’il était impossible de traverser chacun des 7 ponts de la ville russe de Könisberg - Kaliningrad - Калининград une fois exactement et de revenir au point de départ :

De manière générale, un graphe permet de représenter simplement la structure et les cheminements possibles dans un grand nombre de situations, en exprimant les relations et les dépendances entre les éléments : réseau ferroviaire, arbre généalogique, diagramme de succession de tâches en gestion, etc. Au‑delà de son existence purement mathématique, le graphe est aussi une structure de données fondamentale en informatique, indispensable pour résoudre bon nombre de problèmes d’optimisation.
Les sections qui suivent illustrent cette universalité à travers des domaines très différents — linguistique, propriété intellectuelle, physique fondamentale, renseignement, cybersécurité, gestion de versions et programmation visuelle — montrant à chaque fois comment un même formalisme de sommets et d’arcs permet de structurer et d’analyser des réalités complexes.
Influence linguistique
Ce graphe orienté modélise un réseau d’influences entre langues. Chaque sommet représente une langue et chaque arc orienté traduit une relation d’influence historique ou lexicale. Dans une perspective d’introduction à la théorie des graphes, il s’agit d’un exemple simple de digraphe permettant d’illustrer les notions de degré entrant, degré sortant, chemin orienté et structure de réseau.
La modélisation des influences linguistiques sous forme de graphe montre comment un phénomène complexe peut être formalisé en termes mathématiques. L’analyse structurale du digraphe (centralité, connexité, hiérarchie) fournit un cadre rigoureux pour étudier les dynamiques d’influence et les relations de dépendance entre sommets. On peut bien évidemment établir un graphe similaire avec les différents systèmes d’écriture :
Conflits de brevets
Les graphes orientés ne modélisent pas uniquement des phénomènes culturels ou naturels ; ils s’appliquent tout aussi bien aux rapports de force économiques. Le digraphe suivant illustre les relations juridiques entre grandes entreprises technologiques autour de conflits de brevets.
On y observe des poursuites judiciaires fréquentes, notamment entre Apple, Samsung, Microsoft et Motorola, souvent liées aux technologies mobiles. Microsoft adopte une stratégie mixte combinant poursuites et accords de licence, tandis que Kodak, très actif dans les litiges, a aussi résolu plusieurs différends. Ce digraphe met en lumière l’intensité des guerres de brevets dans les années 2010, où la propriété intellectuelle était au cœur des stratégies concurrentielles. L’analyse structurale (degré sortant élevé de Microsoft, arcs bidirectionnels entre Apple et Samsung, composantes de litiges résolus) traduit directement en langage de graphe les dynamiques de pouvoir du secteur.
Projet Wolfram
À une échelle radicalement différente, la théorie des graphes rejoint la physique fondamentale. Selon le Wolfram Physics Project, l’univers lui‑même peut être modélisé comme un hypergraphe évolutif : chaque événement physique représente une mise à jour dans le graphe. Les concepts de courbure, de causalité et d’entrelacement quantique y sont formalisés grâce à des graphes particuliers — causal graphs et branchial graphs — où les sommets et arêtes incarnent des événements et leurs relations causales.
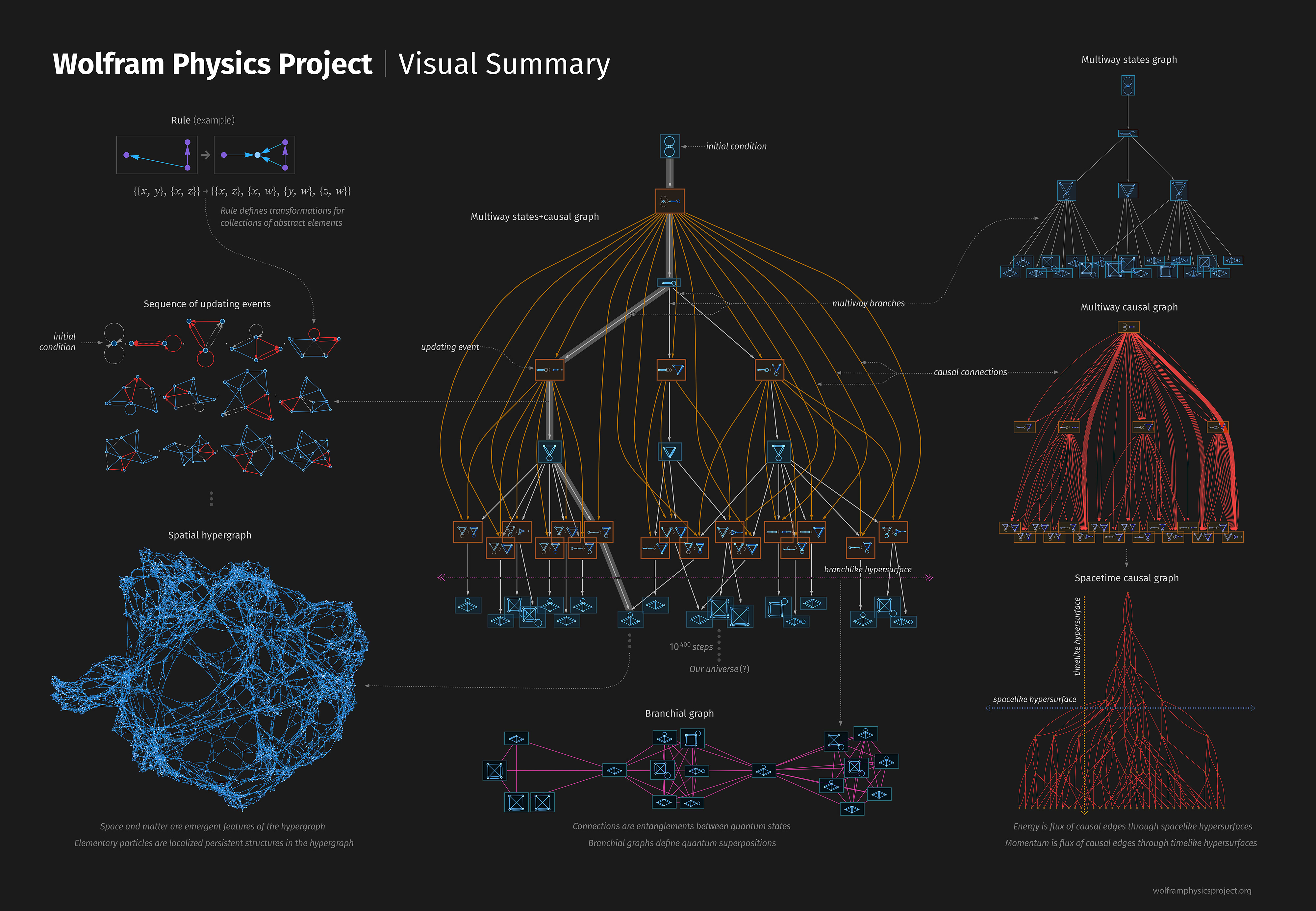
OSINT
Des modèles physiques de l’univers aux réalités opérationnelles du renseignement, le pas est plus court qu’il n’y paraît : dans les deux cas, il s’agit de reconstruire un réseau de relations à partir d’observations fragmentaires.
L’OSINT (Open Source Intelligence) désigne l’art de collecter, corréler et analyser des informations librement accessibles — sites web, réseaux sociaux, registres publics, images satellites, bases de données, fuites de documents — pour produire du renseignement stratégique ou opérationnel. Cette discipline est utilisée aussi bien par les services de renseignement que par des journalistes, ONG, entreprises ou chercheurs, en particulier pour la sécurité nationale, la criminalité transnationale et l’analyse géopolitique.
Formellement, la masse de données OSINT se prête très bien à une modélisation en graphes :
- les sommets représentent individus, comptes, organisations, lieux, numéros, navires, flux financiers, documents, etc. ;
- les arcs (orientés) représentent communications, transactions, déplacements, influences, partages de contenus ou liens logistiques.
Sur ces graphes, on applique des notions de chemin, centralité, communautés ou connexité pour identifier des hubs, des routes privilégiées ou des structures d’influence, exactement dans l’esprit des modèles de réseaux étudiés en théorie des graphes. L’illustration ci‑dessous, issue d’un outil d’analyse, montre comment des points de données hétérogènes peuvent être reliés pour faire émerger un graphe d’enquête : chaque nouvelle information ajoute un sommet ou un arc, et les motifs qui se dessinent orientent ensuite les investigations humaines.

Cartographie réseau : zenmap
L’OSINT et la cybersécurité partagent un même besoin : cartographier un réseau inconnu pour en comprendre la structure. Zenmap, l’interface graphique officielle de Nmap, répond précisément à ce besoin. Plutôt que de se limiter à une liste linéaire d’hôtes et de ports, Zenmap propose une visualisation topologique : les machines découvertes sont représentées comme des sommets, reliés par des arêtes correspondant aux relations réseau (routes, passerelles, sous‑réseaux, segments logiques). La structure globale forme un graphe — non orienté pour les connexions, orienté pour les trajectoires de paquets — permettant de raisonner en termes de composantes connexes, de points de coupure et de chemins minimaux vers une cible.
Git : graphe dynamique
Les exemples précédents présentent des graphes essentiellement statiques (un instantané de relations à un moment donné). Or un graphe n’est pas nécessairement fixe : il peut évoluer dans le temps et conserver la mémoire de cette évolution. C’est précisément ce que fait Git, système de gestion de versions distribué, en représentant l’historique d’un projet comme un graphe orienté acyclique (DAG).
Dans un dépôt Git :
- chaque commit est un sommet ;
- un arc orienté relie un commit à son (ou ses) parent(s), matérialisant la relation « ce commit dérive de celui‑ci ».
Les branches sont alors simplement des pointeurs vers certains sommets, et les fusions (merge) créent des nœuds à plusieurs parents, tout en préservant l’acyclicité globale du graphe (on ne revient jamais en arrière dans le temps logique du dépôt). Cette structure permet de :
- modéliser naturellement des chemins (historique linéaire d’une branche) ;
- raisonner sur des divergences (branches qui se séparent, se rejoignent) ;
- appliquer des opérations comme le rebase ou le cherry‑pick, qui reviennent à réécrire localement des chemins dans le graphe.
Les visualisations de l’historique Git rendent explicite ce graphe sous‑jacent : on y voit les commits comme des nœuds colorés, reliés par des arcs, avec différentes branches qui se croisent et se rejoignent. C’est un excellent exemple d’application dynamique de la théorie des graphes, montrant comment une structure mathématique abstraite intervient dans un outil quotidien des développeurs.
On peu évidement visualiser qui modifie quoi et quand dans une branche :
Outils no‑code et graphes visuels
Dans la continuité de la théorie des graphes, de nombreux outils dits no‑code ou low‑code proposent une programmation entièrement visuelle, où l’on compose des comportements en connectant des blocs entre eux. Chaque bloc (ou nœud) représente une opération (événement, calcul, condition, action), et les liens entre blocs représentent les dépendances de contrôle ou de données. On manipule donc, explicitement, un graphe orienté : les nœuds sont les unités de logique, les arcs sont les flux d’exécution ou d’information.
Ce paradigme présente plusieurs avantages :
- il rend visibles les chemins d’exécution (on voit littéralement le chemin parcouru dans le graphe)
- il force à raisonner en termes de structure et de dépendances plutôt qu’en syntaxe textuelle
- il facilite l’expérimentation, car modifier un comportement revient à ajouter, déplacer ou reconnecter un nœud dans le graphe
- on s’épargne les temps de compilation.
Blueprint d’Unreal Engine
Les Blueprints d’Unreal Engine illustrent parfaitement cette approche nodale. Un Blueprint est un graphe où :
- chaque sommet est un nœud de type « événement » (BeginPlay, Tick, input clavier/souris), « fonction », « macro », « variable » ou « opérateur » ;
- chaque arc relie un nœud à un autre, soit pour transmettre le flux d’exécution (fils blancs), soit pour transporter des valeurs (fils colorés selon le type de donnée).
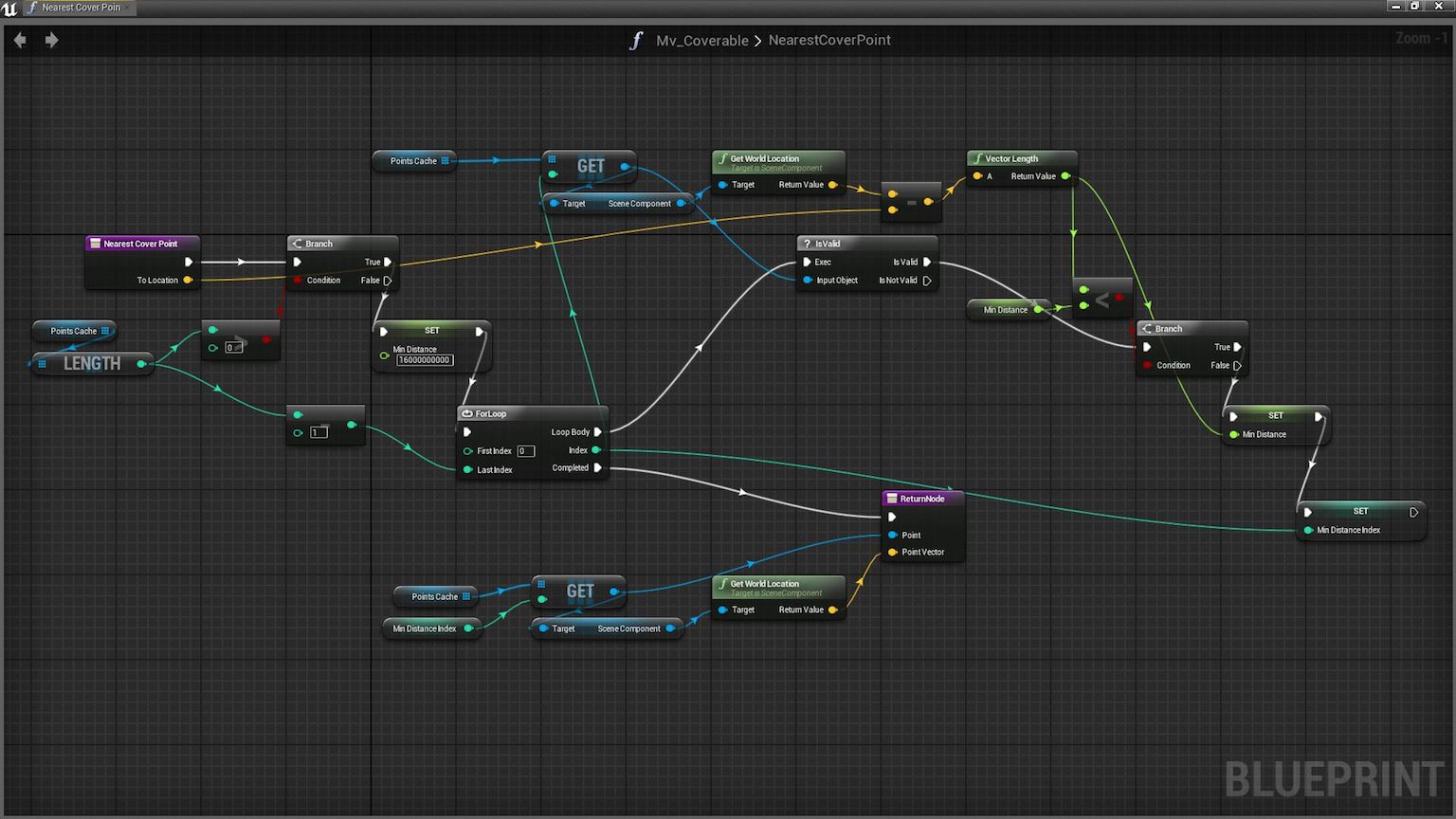
On peut formaliser un Blueprint comme un digraphe $G = (X, U)$ où $X$ est l’ensemble des nœuds visuels et $U$ l’ensemble des connexions orientées. Une séquence d’actions déclenchée par un événement correspond à un chemin, une logique répétée (Tick, boucle) correspond à un cycle, et un sous‑système réutilisable (fonction, macro) correspond à un sous‑graphe. L’idée fondamentale : sans écrire une seule ligne de code, on manipule déjà des graphes au sens mathématique. Nous reviendrons sur ces notions dans une secondes partie.
Compilation et vérification
Derrière l’interface « no‑code », un moteur comme Unreal compile les Blueprints vers une forme plus bas niveau (bytecode, C++ généré, ou représentation interne) afin de les exécuter efficacement. On retrouve ici la séparation classique entre :
- un front‑end : la représentation visuelle en graphe (Blueprint Graph) ;
- un back‑end : la traduction de ce graphe en instructions exécutables sur une machine virtuelle ou directement en code natif.
La plupart des compilateurs textuels font déjà quelque chose de similaire : ils construisent un graphe de flot de contrôle (CFG) et un graphe de flot de données pour optimiser et vérifier le programme (détection de chemins morts, simplification, analyse de dépendances). Les environnements no‑code rendent simplement ce graphe visible à l’utilisateur, mais le cœur théorique reste le même.
Cette représentation graphique ouvre aussi la porte à des méthodes de vérification formelle basées sur les graphes :
- s’assurer qu’il n’existe pas de chemin menant à un état interdit (erreur, deadlock) ;
- vérifier que certains cycles ne peuvent pas se produire (boucles infinies) ;
- appliquer des règles de transformation de graphes pour prouver des propriétés sur le comportement du système (correction, absence de blocage, respect de contraintes).
En résumé, les outils no‑code comme les Blueprints d’Unreal Engine sont une excellente illustration moderne de la théorie des graphes appliquée : l’utilisateur dessine un digraphe, le moteur le compile, et les techniques de compilation et de vérification exploitent justement cette structure graphique pour optimiser et contrôler le programme.
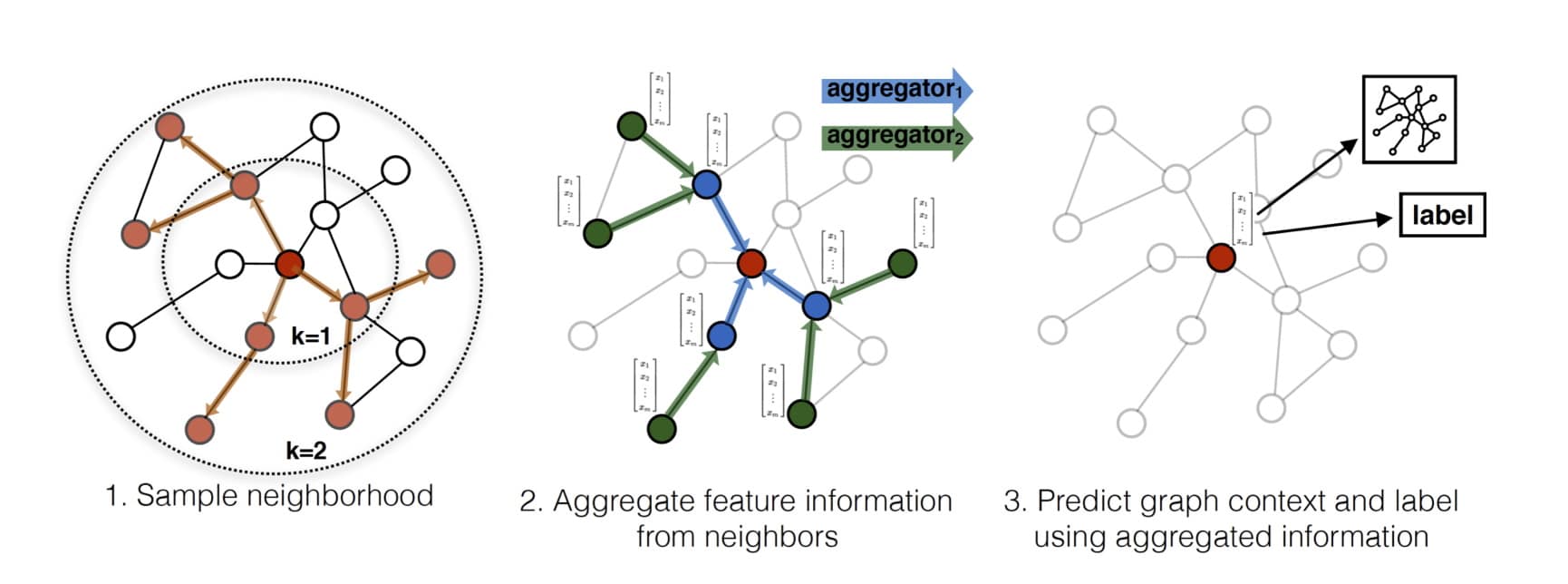
Réseaux de neurones
Les graphes ne servent pas seulement à modéliser des structures statiques : ils sont aussi devenus un support de données pour le deep learning. L’idée des Graph Neural Networks (GNN) est d’apprendre une représentation de chaque sommet (embedding) en tenant compte non seulement de ses propres attributs, mais aussi de ceux de ses voisins, via un mécanisme de passage de messages.
Un cas particulier très utilisé est le Graph Convolutional Network (GCN). On peut le voir comme l’analogue d’un CNN pour des données non euclidiennes : au lieu de faire une convolution sur une grille de pixels, on agrège les informations sur le voisinage dans le graphe (successeurs, prédécesseurs, $k$-voisinage, etc.). À chaque couche, la représentation d’un sommet $x_i$ est mise à jour à partir de lui-même et de ses voisins, ce qui revient à appliquer une opération du type :
$$h_i^{(k+1)} = \text{AGGR}\big(h_i^{(k)}, \{h_j^{(k)} \mid j \in \Gamma(i)\}\big)$$
où $\Gamma(i)$ est l’ensemble des voisins (liste d’adjacence) et AGGR une fonction d’agrégation (moyenne, somme, attention, …). Ce formalisme relie directement la matrice d’adjacence du cours aux opérations d’un réseau de neurones.
Applications typiques : classification de nœuds (détecter des comptes frauduleux dans un réseau social), prédiction de liens (recommandation d’amis), classification de graphes (reconnaître une molécule toxique ou non, à partir de son graphe d’atomes).
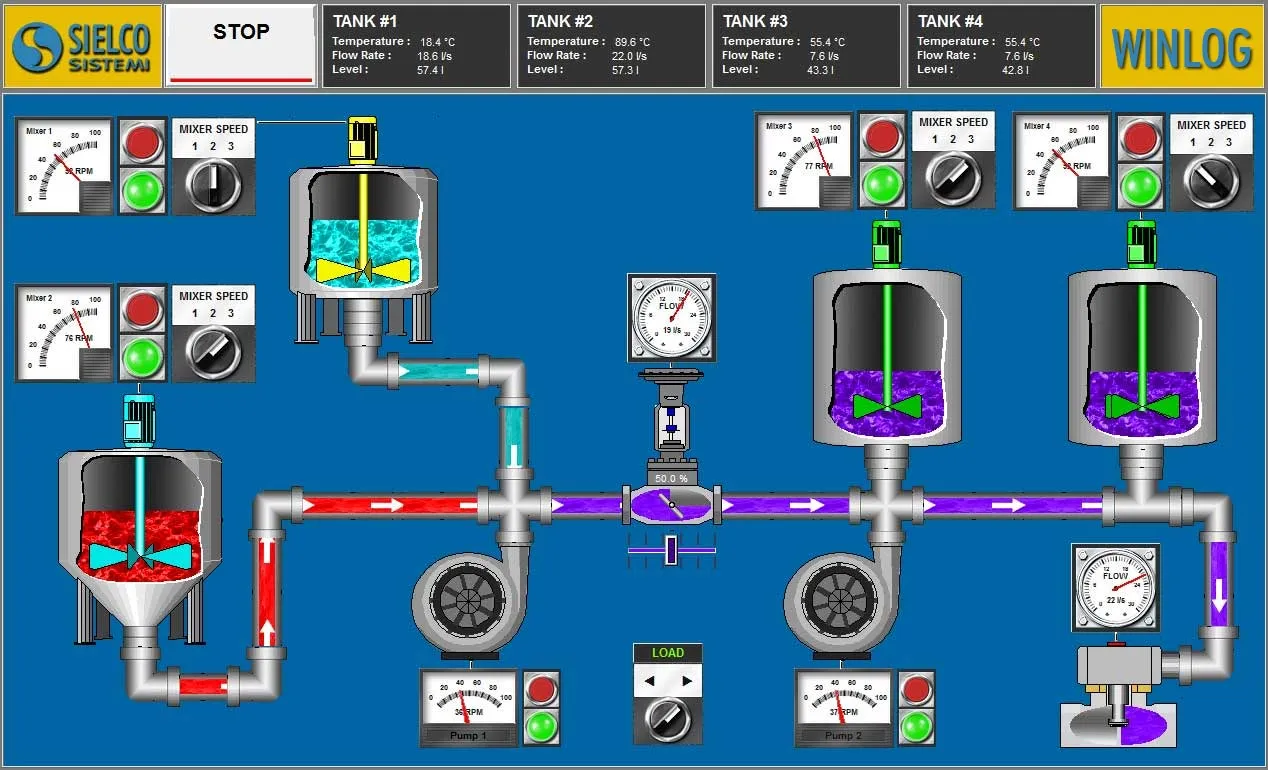
Jumeaux numériques
Un jumeau numérique est un modèle numérique qui reflète un système physique : machine industrielle, ligne de production, bâtiment, voire patient. On y retrouve naturellement la structure de graphe :
- les sommets représentent les composants : machines, sous-ensembles, capteurs, contrôleurs, opérateurs ;
- les arcs représentent les interconnexions : flux de matière, énergie, informations, dépendances logiques ou causales ;
- chaque sommet et chaque arc portent des mesures issues des capteurs (température, vibration, courant, débit, état on/off, etc.).
Dans ce contexte, un triptyque simple est :
machine + capteurs + interconnexions = graphe du jumeau numérique. De plus une hierachie peut-être définie :

Une fois ce graphe construit, la théorie des graphes devient un outil pour la root cause analysis (analyse de cause racine) :
- la propagation d’un défaut se lit comme un chemin ou un sous-graphe activé par des anomalies de capteurs ;
- les sommets de forte centralité ou appartenant à de nombreux cycles sont de bons candidats pour des causes profondes ;
- la fermeture transitive ou des algorithmes de parcours (DFS/BFS) permettent de remonter des symptômes (capteur en alarme) vers les composants qui peuvent en être la source ;
- des modèles type GNN/GCN peuvent ensuite apprendre, à partir de l’historique, quels motifs de graphe sont associés à telle ou telle panne.
Exemple de jumeaux numérique utilisant SCADA :