Représentation d’un graphe
Il existe plusieurs types de représentation pour décrire un graphe. On distingue principalement la représentation par matrice d’adjacence, par matrice d’incidence sommet-arcs et par liste d’adjacences (ou encore jerryyin.info et autre structure optimisé souvent plus éxotique). Chacune de ces représentations a ses avantages : certaines sont plus adaptées au calcul matriciel, profite de la localité cache, d’autres à l’implémentation efficace en mémoire ou encore optimisation mémoire.
Matrice d’adjacence
Pour un 1-graphe d’ordre $n$, on numérote les sommets $x_1, \dots, x_n$ et l’on construit une matrice $A = (a_{ij})_{1 \le i,j \le n}$ :
- les lignes correspondent aux sommets d’origine ;
- les colonnes correspondent aux sommets de destination.
Dans un formalisme booléen :
- $a_{ij} = 1$ s’il existe un arc $(x_i, x_j)$ ;
- $a_{ij} = z$ dans le cas pondéré
- $a_{ij} = 0$ sinon.
Dans un formalisme pondéré, $a_{ij}$ peut contenir le poids de l’arc $(x_i, x_j)$ ; en l’absence d’arc, on fixe souvent une valeur spéciale (par exemple $0$ ou $-1$) pour signaler « pas de liaison ». Cette représentation est très utilisée, notamment parce que :
- le degré sortant de $x_i$ est la somme de la ligne $i$ ; a adapter au cas pondéré
- le degré entrant de $x_j$ est la somme de la colonne $j$ ; a adapter au cas pondéré
- la puissance $A^k$ encode le nombre de chemins de longueur $k$ entre deux sommets (coefficient $(i,j)$).
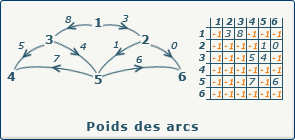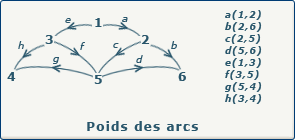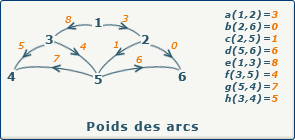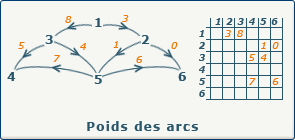
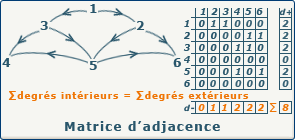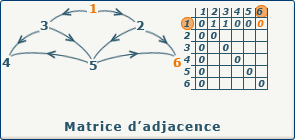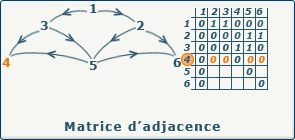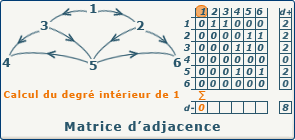
source : gaudry.be
Par exemple, on peut simplement utiliser une matrice NumPy pour ce type de représentation :
n = 4 # number_of_nodes
connection = np.zeros((n, n))
connection[0, 0] = 1 # boucle sur x_1
connection[0, 2] = 1 # arc de x_1 -> x_3
# etc ...
Tres similaire que nous verron plus tard, les matrices laplacienne
Exemple de matrice d’adjacence
On numérote les sommets $x_1, x_2, x_3$ par $1,2,3$ (ou $0,1,2$ en Python) et on construit $A = (a_{ij})$ avec $a_{ij} = 1$ s’il existe un arc de $x_i$ vers $x_j$, $0$ sinon. Dans l’ordre $(x_1, x_2, x_3)$. En NumPy, avec indexation à partir de 0 :
import numpy as np
n = 3 # 3 sommets
A = np.zeros((n, n), dtype=int)
# x1 -> x2
A[0, 1] = 1
# x2 -> x3
A[1, 2] = 1
# x1 -> x3
A[0, 2] = 1
Matrice d’incidence sommet-arc
Pour établir cette matrice, les lignes sont constituées des sommets du graphe et les colonnes des arcs. On pose la valeur 1 pour le sommet d’origine et -1 pour le sommet de destination. Dit autrement, on numérote les sommets $x_1, \dots, x_n$ et les arcs $u_1, \dots, u_m$, puis on construit une matrice $B = (b_{ik})_{1 \le i \le n, 1 \le k \le m}$ :
- les lignes représentent les sommets ;
- les colonnes représentent les arcs.
Pour un graphe orienté, on adopte la convention suivante :
- $b_{ik} = 1$ si le sommet $x_i$ est origine de l’arc $u_k$ ;
- $b_{ik} = -1$ s’il en est la destination ;
- $b_{ik} = 0$ sinon.
Pour un graphe non orienté, on utilise souvent $(1,1)$ ou $(1,-1)$ selon la convention choisie.
Encore une fois, une simple matrice NumPy peut être utilisée. Cependant, ce type de représentation est moins flexible à la modification (ajout/suppression d’arcs plus coûteux). Necessite une reallocation memoire importante et un copie global.
n = 2 # number_of_nodes
m = 1 # number_of_arcs
connection = np.zeros((n, m))
connection[0, 0] = -1 # arc de x_1
connection[1, 0] = 1 # vers x_2
Exemple de matrice d’incidence
Sur un petit graphe orienté à 3 sommets et 3 arcs $x_1 \xrightarrow{u_1} x_2$, $x_2 \xrightarrow{u_2} x_3$, $x_1 \xrightarrow{u_3} x_3$. La somme des entrées de chaque colonne est nulle, ce qui reflète le fait qu’un arc a exactement un sommet d’origine et un de destination. En Python, on peut coder cela via une matrice dense :
import numpy as np
n, m = 3, 3 # 3 sommets, 3 arcs
B = np.zeros((n, m), dtype=int)
# u1 : x1 -> x2
B[0, 0] = 1
B[1, 0] = -1
# u2 : x2 -> x3
B[1, 1] = 1
B[2, 1] = -1
# u3 : x1 -> x3
B[0, 2] = 1
B[2, 2] = -1
Liste d’adjacence
L’objectif ici est de représenter chaque arc par son extrémité finale, l’extrémité initiale étant définie implicitement. Tous les arcs émanant d’un même sommet sont liés dans une liste. À chaque arc sont associés le sommet de destination et un pointeur vers le suivant. Pour un 1-graphe, la représentation par liste d’adjacence est avantageuse (on exploite l’application multivoque $\Gamma$) car elle permet un gain de mémoire par rapport à la matrice d’adjacence.
Idée :
- pour chaque sommet $i$, on stocke la liste $\Gamma(i)$ de ses successeurs ;
- la structure est très compacte si le graphe est creux (peu d’arcs par rapport à $n^2$) ;
- l’ajout / suppression d’arcs est généralement peu coûteux.
Dans les implémentations classiques (type FORTRAN/C), on utilise deux tableaux :
- $LP$ (ListePointeur) de taille $n+1$ ;
- $LS$ (ListeSuccesseurs) de taille $m$ pour un graphe orienté, ou $2m$ pour un graphe non orienté (car chaque arête donne deux successeurs).
Pour chaque sommet $i$, la liste des successeurs est contenue dans le tableau $LS$ à partir de l’indice $LP[i]$. Les informations du sommet $i$ se trouvent dans les cases $LS[LP[i]]$ à $LS[LP[i+1]-1]$.
- les successeurs sont stockés dans $LS$ entre les indices $LP[i]$ et $LP[i+1]-1$ ;
- le nombre de successeurs vaut $w^{+}(i) = LP[i+1] - LP[i].$
- on peut calculer $LP$ par : $LP = 1, \quad LP[i] = 1 + \sum_{j=1}^{i-1} w^{+}(j) \quad \text{pour } i \ge 2.$
- si un sommet $i$ n’a aucun successeur, on impose $LP[i] = LP[i+1]$ (liste vide).
Cette représentation revient à décrire le graphe par son application multivoque $i \mapsto \Gamma(i)$.
Exemple de graph
Version plus simple et plus flexible en Python :
nodes = [[] for _ in range(number_of_nodes)]
nodes[0] = [1] # successeurs de x_1
nodes[1] = [0, 2] # successeurs de x_2
nodes[2] = [0, 1, 4]
nodes[3] = [2]
nodes[4] = [5]
nodes[5] = [2, 5] # boucle locale
Dans cette version :
adj[i]contient la liste des successeurs du sommet $x_{i+1}$ ;- une boucle sur un sommet $x_k$ se traduit par la présence de $k$ (ou $k-1$ selon l’indexation) dans sa propre liste.
Cependant, ce type de représentation ne permet pas de modéliser directement le poids des arcs. Il faut ajouter un tableau supplémentaire, similaire à $LS$, pour contenir les poids. On peut aussi aller plus loin en utilisant des classes. Voir aussi compresser les structures jerryyin.info