L’informatique moderne trouve ses racines dans l’exécution séquentielle de Von Neumann, où un processeur exécute une instruction après l’autre. Cette approche, bien qu’élégante dans sa simplicité, s’est rapidement heurtée aux limites de performance lorsque les applications ont commencé à nécessiter des traitements simultanés. L’émergence des interfaces utilisateur graphiques dans les années 1980, puis des serveurs web dans les années 1990, a créé une demande pressante pour des systèmes capables d’effectuer plusieurs tâches simultanément.
Ce cours présente les concepts fondamentaux de gestion des processus et d’ordonnancement dans les systèmes d’exploitation modernes, depuis la création d’un processus jusqu’aux algorithmes d’allocation de ressources. La correspondance avec Java illustre comment ces concepts universels s’appliquent en programmation.
Dans le cadre de ce cours, nous nous concentrons principalement sur les systèmes UNIX/Linux, avec quelques références aux spécificités Windows lorsque pertinentes. Les exemples Java fournis utilisent les API standard disponibles depuis Java 8+.
Qu’est ce qu’un programme
Un programme est une entité passive : il s’agit d’un ensemble d’instructions, généralement écrit dans un langage de programmation, qui définit un protocole ou une séquence d’opérations à réaliser pour atteindre un résultat donné. Le programme est stocké sous forme de fichier (dans la mémoire de masse ou secondaire) et reste inactif tant qu’aucun système n’en lance l’exécution.
Un programme n’est jamais universel : il est conçu pour une cible particulière.
- Il peut être lié à un système d’exploitation (Windows, Linux, macOS, etc.).
- Il peut aussi dépendre d’une architecture matérielle (x86, ARM, etc.).
Un programme compilé n’est pas qu’une suite d’instructions ; c’est un ensemble organisé de données et de métadonnées réparties entre plusieurs zones structurantes au sein du fichier exécutable. Chaque système possède son propre format binaire pour organiser les données, le code, les informations sur l’agencement mémoire, le point d’entrée, etc. :
- Java : le code source est transformé en bytecode. Ce bytecode est ensuite interprété par la JVM (Java Virtual Machine), qui elle-même est un programme compilé spécifiquement pour chaque système hôte (Linux, Windows, macOS…). Par exemple, la JVM pour Linux utilise le format ELF, alors que sous Windows, elle adopte le format PE (Portable Executable).
- Python ou autres langages interprétés/transpilés : le code source peut être transformé en bytecode ou interprété directement, à travers un loader dédié.
- Langages compilés pour le système hôte (C, C++, Rust…) : la compilation s’appuie sur la nomenclature binaire du système cible.
Lors du lancement d’un éxécutable, le Loader associé lit l’entête, réserve la mémoire nécessaire, charge les dépendances, applique les relocations, et enfin transfère l’exécution au point d’entrée (la fameuse fonction main).
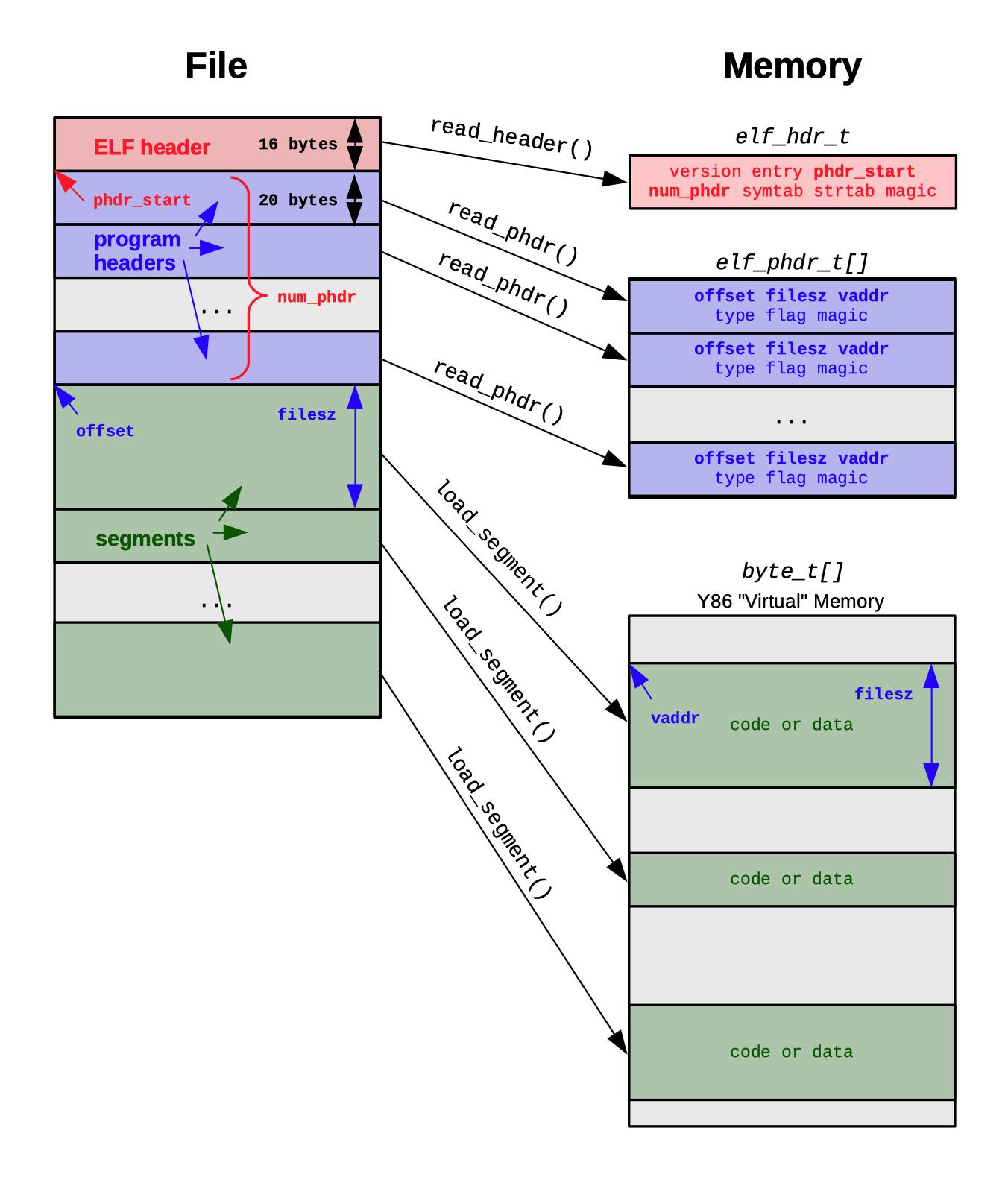
Linux - ELF
Le format standard est ELF (Executable and Linkable Format) :
- Un fichier exécutable ELF structure très précisément toutes les parties du programme :
- ELF Header : identifie le type de fichier, l’architecture matérielle, la version du format, le point d’entrée
- Program Header Table : décrit les segments à charger en mémoire pour que le programme fonctionne (code, données initialisées, zones non initialisées)
- Sections : organisent les symboles, chaînes, tables de relocation, information de debug
- Lors du lancement, l’OS lit ces structures pour initialiser le processus, allouer la mémoire et transférer le contrôle au code utilisateur.
Ainsi, le programme selon le format ELF (ou tout autre standard équivalent) n’est pas uniquement une séquence d’instructions, mais un objet structuré, prêt à devenir un processus actif au sein du système cible, via le mécanisme de chargement et d’exécution approprié.
Windows - PE
Le principe est similaire pour Windows, les exécutables utilisent le format PE (Portable Executable) (utilisé pour les .exe, .dll, .sys…) et dérivé de l’ancien format COFF . Sa structure contient :
- MS-DOS Header : compatibilité héritée (contient un stub qui affiche “This program cannot be run in DOS mode”).
- PE Header : informations sur l’architecture (x86, x64, ARM), les sections, les bibliothèques nécessaires.
- Section Table : décrit les segments (
.textpour le code,.datapour les données,.rdatapour les constantes,.rsrcpour les ressources comme icônes, menus, etc.). - Import/Export Tables : gèrent les fonctions importées/exportées (par exemple
kernel32.dll,user32.dll), indispensable au modèle Windows basé sur les DLL.

Du programme au processus
La transformation d’un programme statique, stocké sur une mémoire persistante, en un programme en cours d’exécution introduit la notion d’instance. Chaque instance correspond à un processus : elle possède son propre état et ses propres variables, et évolue indépendamment des autres instances du même programme. Ainsi, l’instanciation d’un programme crée un processus actif.
Lorsqu’un utilisateur lance un programme, le noyaux orchestre une série d’opérations pour créer un nouvel espace d’exécution. Le processus débute par un appel système (fork() et execvp() sous Unix/Linux) qui demande au noyau de créer une nouvelle instance d’exécution.
Le noyau analyse ensuite le format du fichier exécutable (ELF sous Linux, PE sous Windows) pour identifier les sections de code, les données statiques, les dépendances dynamiques et le point d’entrée du programme. Une fois cette analyse terminée, le système alloue les segments mémoire nécessaires : le segment de code (instructions), le segment de données (variables globales), le tas (heap) pour l’allocation dynamique, et la pile (stack) pour les variables locales et les appels de fonctions.
Puis passe a l’éxécution :
Hiérarchie de Processus
La gestion des processus dans un système d’exploitation moderne repose sur une architecture hiérarchique qui reflète les relations de parenté entre les différents programmes en cours d’exécution. Cette organisation permet un contrôle fin des ressources et une gestion cohérente du cycle de vie des applications.
Multiplicité des instances : Un aspect fondamental est qu’un même programme peut donner naissance à plusieurs processus indépendants fonctionnant simultanément. Par exemple, ouvrir plusieurs fenêtres d’un navigateur web crée autant de processus distincts, chacun avec son propre espace mémoire et ses propres ressources.
Relations parent-enfant : Les processus peuvent créer d’autres processus, établissant une relation de parenté. Le processus créateur devient le “processus parent” et le nouveau processus devient le “processus fils”. Cette relation persiste tout au long de l’existence du processus enfant et influence notamment la gestion des signaux et la récupération des codes de retour.
Arborescence système : L’ensemble des processus actifs forme une structure arborescente dont la racine est le processus initial du système. Sous Linux, ce processus racine est généralement init (PID 1) ou systemd, responsable du démarrage et de la supervision des services système fondamentaux.
Interaction shell-commandes : Un exemple concret de cette hiérarchie se manifeste dans l’utilisation d’un terminal. Le shell lui-même constitue un processus, et chaque commande exécutée dans ce shell engendre un processus fils. Une fois la commande terminée, le processus fils se termine et communique son état de sortie au processus parent (le shell).
Cette organisation hiérarchique permet au système d’exploitation de maintenir la cohérence lors des opérations critiques comme l’arrêt du système ou la gestion des ressources partagées. Lorsqu’un processus parent se termine anormalement, le système peut prendre des décisions appropriées concernant ses processus enfants.
Chaque processus possède un identifiant unique appelé PID (Process ID). Lorsqu’un processus crée un nouveau processus (via fork(), execvp() ou équivalent), le processus enfant conserve l’identifiant de son créateur dans le champ PPID (Parent Process ID). Ainsi, PID identifie le processus lui-même, tandis que PPID identifie son parent. Pour le processus racine du système (souvent init ou systemd), il n’a pas de parent réel et PID = PPID = 1.
Cycle de vie
Principe fondamental : Pour comprendre la gestion multitâche, imaginez orchestrer simultanément plusieurs activités sur votre ordinateur - écouter de la musique, naviguer sur Internet, et rédiger un document. Le système d’exploitation accomplit cette prouesse en créant des processus, unités d’exécution autonomes qui permettent le suivi et le contrôle précis de chaque programme en cours d’exécution.
Les états d’un processus
La gestion efficace des ressources système repose sur un modèle d’états qui décrit précisément la situation de chaque processus à tout moment. Cette classification permet à l’ordonnanceur du système d’exploitation d’optimiser l’utilisation du processeur et de garantir une répartition équitable du temps de calcul.
Nouveau (New) : Phase d’initialisation où le processus vient d’être créé mais n’a pas encore intégré la liste des processus éligibles à l’exécution. Durant cette phase, le système d’exploitation alloue les ressources mémoire nécessaires, initialise le Process Control Block (PCB) qui contiendra toutes les informations de gestion du processus, et effectue les vérifications de sécurité et de permissions.
Prêt (Ready) : État d’attente active où le processus possède toutes les ressources requises pour son exécution, à l’exception du temps processeur. Le processus est entièrement chargé en mémoire, ses dépendances sont résolues, et il attend simplement d’être sélectionné par l’ordonnanceur. Plusieurs processus peuvent coexister dans cet état, organisés selon différentes stratégies de files d’attente (priorité, round-robin, etc.).
En Exécution (Running) : État actif où le processus utilise effectivement le processeur pour exécuter ses instructions. Dans un système monoprocesseur, cet état ne peut être occupé que par un seul processus à la fois. Dans un système multiprocesseur, le nombre de processus simultanément en exécution est limité par le nombre de cœurs disponibles.
Bloqué (Blocked/Waiting) : État de suspension où le processus attend la disponibilité d’une ressource externe indispensable à la poursuite de son exécution. Cette situation se produit typiquement lors d’opérations d’entrée/sortie (lecture fichier, accès réseau), d’attente de signaux, ou de synchronisation avec d’autres processus. Le processus ne peut reprendre son exécution tant que l’événement attendu ne se produit pas.
Terminé (Terminated) : État final où l’exécution du processus est achevée, soit normalement soit à la suite d’une erreur ou d’une interruption forcée. Les ressources allouées (mémoire, fichiers ouverts, etc.) sont libérées, mais le PCB peut temporairement persister pour permettre au processus parent de récupérer les informations de fin d’exécution (code de retour, statistiques d’utilisation).
Transitions entre états
L’ordonnanceur du système d’exploitation contrôle rigoureusement les transitions entre ces différents états selon des règles bien définies :
Élection (Dispatch) : Transition de l’état Prêt vers En Exécution lorsque l’ordonnanceur sélectionne le processus selon sa politique de planification (priorité, temps d’attente, équité, etc.).
Préemption (Preemption) : Transition forcée de l’état En Exécution vers Prêt, généralement déclenchée par l’expiration du quantum de temps alloué au processus ou par l’arrivée d’un processus de priorité supérieure.
Blocage (Block) : Transition de l’état En Exécution vers Bloqué lorsque le processus demande une ressource momentanément indisponible ou initie une opération nécessitant une attente (E/S, synchronisation).
Déblocage (Unblock) : Transition de l’état Bloqué vers Prêt lorsque la ressource attendue devient disponible ou que l’événement attendu se produit. Le processus redevient éligible à l’exécution.
Représentation graphique
Implémentation en Java
L’API Process de Java (introduite et enrichie depuis Java 9) offre des mécanismes sophistiqués pour la gestion et la surveillance des processus externes. Cette approche permet un contrôle fin du cycle de vie des processus lancés depuis une application Java.
import java.io.IOException;
import java.util.concurrent.TimeUnit;
public class ProcessExample {
public static void main(String[] args) {
try {
ProcessBuilder pb = new ProcessBuilder("ls", "-la");
Process process = pb.start();
if (process.isAlive())
System.out.println("Processus en cours");
int exitCode = process.waitFor();
System.out.println("Processus terminé avec le code : " + exitCode);
// Gestion avec timeout (évite le blocage infini)
boolean finished = process.waitFor(5, TimeUnit.SECONDS);
if (!finished) {
process.destroyForcibly(); // Termine le processus
System.out.println("Processus terminé de force (timeout dépassé).");
}
} catch (IOException | InterruptedException e) {
e.printStackTrace();
}
}
}
Implémentation en C
L’implémentation en C utilise directement les appels système POSIX, offrant un contrôle de bas niveau sur la création et la gestion des processus. Cette approche révèle les mécanismes fondamentaux utilisés par le système d’exploitation.
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <sys/wait.h>
#include <signal.h>
int main() {
pid_t pid = fork();
if (pid < 0) {
perror("Erreur lors du fork");
return 1;
}
if (pid == 0) {
// Processus enfant : exécute la commande "ls -la"
char *args[] = {"ls", "-la", NULL};
execvp(args[0], args);
// Si exec échoue
perror("Erreur execvp");
exit(1);
} else {
// Processus parent : surveille l'enfant
printf("Processus en cours d'exécution (PID = %d)\n", pid);
int status;
// Timeout de 5 secondes
int timeout = 5;
pid_t result;
for (int i = 0; i < timeout; i++) {
result = waitpid(pid, &status, WNOHANG);
if (result == 0) {
// L'enfant est encore vivant
sleep(1);
} else {
break;
}
}
// Si après 5 secondes il est encore vivant → on le tue
result = waitpid(pid, &status, WNOHANG);
if (result == 0) {
printf("Processus trop long, terminaison forcée.\n");
kill(pid, SIGKILL);
waitpid(pid, &status, 0); // récupérer le code de sortie
}
if (WIFEXITED(status)) {
printf("Processus terminé avec le code : %d\n", WEXITSTATUS(status));
} else if (WIFSIGNALED(status)) {
printf("Processus tué par le signal : %d\n", WTERMSIG(status));
}
}
return 0;
}
Cette implémentation illustre la création d’un processus enfant via fork(), son remplacement par un nouveau programme via execvp(), et la surveillance de son exécution par le processus parent avec gestion de timeout et récupération du code de sortie.
L’Ordonnancement (Scheduling)
Problème : Un processeur ne peut faire qu’une seule chose à la fois, mais nous voulons utiliser plusieurs programmes simultanément. Cette contrainte physique impose la nécessité d’un ordonnanceur (scheduler) qui décide quel processus doit s’exécuter à chaque instant.
Solution : Le système d’exploitation fait du “multitâche” en donnant tour à tour le processeur à chaque programme, très rapidement (millisecondes). Cette technique crée l’illusion que tous les programmes s’exécutent simultanément.
L’ordonnanceur doit satisfaire plusieurs objectifs parfois contradictoires :
- Équité : S’assurer que chaque processus reçoive sa part de temps processeur
- Efficacité : Utiliser le processeur à 100% pour éviter le gaspillage de ressources
- Temps de réponse : Minimiser le délai entre une requête et sa réponse
- Débit : Maximiser le nombre de processus terminés par unité de temps
- Prédictibilité : Garantir des performances cohérentes
Algorithmes d’ordonnancement sans préemption
FIFO (First In, First Out)
L’algorithme FIFO, également appelé FCFS (First-Come, First-Served), représente l’approche la plus simple : les processus sont exécutés strictement dans leur ordre d’arrivée. Une fois qu’un processus commence son exécution, il la termine complètement avant qu’un autre ne puisse prendre la main.
- Avantages :
- Simplicité d’implémentation
- Pas de risque de famine (starvation)
- Prévisible et juste dans l’ordre d’arrivée
- Inconvénients :
- Effet convoi : Un processus long bloque tous les suivants
- Temps d’attente moyen élevé si les processus courts arrivent après les longs
- Non optimal pour les systèmes interactifs
P1 P2 P3
0----24----27--30
0-----3------6--30
- Temps d’attente : P1=0, P2=24, P3=27 → Moyenne = 17 unités
- Temps de rotation : P1=24, P2=27, P3=30 → Moyenne = 27 unités
- Temps d’attente moyen = (0+3+6)/3 = 3 unités (amélioration de 82% !)
SJF (Shortest Job First)
L’algorithme SJF sélectionne toujours le processus ayant le temps d’exécution le plus court parmi ceux disponibles dans la file d’attente. Cet algorithme est mathématiquement optimal pour minimiser le temps d’attente moyen.
- Avantages :
- Temps d’attente moyen minimal (optimal)
- Favorise les processus courts
- Bon débit pour les petites tâches
- Inconvénients :
- Nécessite de connaître à l’avance la durée d’exécution
- Risque de famine pour les processus longs
- Non adapté aux systèmes temps réel (pas de gestion de la criticité)
P4 P1 P3 P2
0---3-------9--------16-------24
Algorithmes d’ordonnancement avec préemption
Chaque processus reçoit un quantum de temps fixe (typiquement 20-30ms). Si le processus ne se termine pas dans ce délai, il est interrompu / préempté et remis en fin de file d’attente.
Choix du quantum : Un quantum trop petit provoque trop de commutations (overhead), un quantum trop grand se rapproche de FIFO et dégrade la réactivité.
Round Robin (Tourniquet)
Rien de particulié, chaque processus est éxécuté dans l’odre pendant un quantum de temps fixe. P1 P2 P3, P1 P2 P3 .... C’est donc une file circulaire de processus prêts. Certaines opérations (E/S, syscall, synchro) mettent fin directement au quantum).
- Avantages :
- Équitable : tous les processus reçoivent la même part de processeur
- Bonne réactivité pour les systèmes interactifs
- Évite la famine
- Temps de réponse borné
- Inconvénients :
- Surcharge due aux changements de contexte fréquents
- Performance dépend fortement de la taille du quantum
- Peut pénaliser les processus courts
Ordonnancement par priorités
Chaque processus possède une priorité numérique. L’ordonnanceur sélectionne toujours le processus de plus haute priorité parmi ceux qui sont prêts.
Les priorités statiques sont fixées dès la création du processus et ne changent pas durant son exécution. Cette méthode est simple à mettre en œuvre, mais elle reste rigide et peut engendrer des problèmes importants, notamment un risque élevé de famine pour les processus ayant une faible priorité, qui peuvent se voir indéfiniment retardés si des processus de plus haute priorité continuent d’arriver.
Les priorités dynamiques avec vieillissement permettent un ajustement continu en fonction du comportement du processus. Ainsi, les processus qui restent en attente voient progressivement leur priorité augmenter, ce qui garantit qu’ils finissent par être exécutés. Ce mécanisme constitue une solution efficace pour prévenir la famine et assurer une meilleure équité dans la répartition des ressources.
Algorithmes Modernes
Les systèmes modernes utilisent des files de priorités multiples où :
- Chaque niveau de priorité a sa propre file Round Robin
- Les processus peuvent migrer entre niveaux selon leur comportement.
- Les processus interactifs montent en priorité, les processus CPU-intensifs descendent.
Politique d’ordonnancement Windows
Windows adopte une approche de load balancing agressif qui privilégie l’utilisation uniforme des cœurs. Lorsqu’un processus est en exécution, l’ordonnanceur le déplace volontiers d’un cœur à un autre pour profiter de cœurs momentanément “peu chargés” (load balancing).
- Windows ne fait pas toujours la distinction entre un cœur physique et un cœur logique (SMT/Hyperthreading).
- L’ordonnanceur de Windows ne prend pas en compte la topologie avancée des CPU modernes.
- Il peut déplacer des threads entre des “groupes” de cœurs ayant des caches séparés (CCX, NUMA), sans se soucier du coût.
- Conséquence:
- Un programme (même monothread) peut être migré d’un cœur à un autre fréquemment (typiquement toutes les 40 millisecondes) :
- Chaque migration de thread détruit l’état du cache de données du processeur, générant des “cache misses”.
- Cela provoque donc des ralentissements, particulièrement pour les applications sensibles à la latence ou à la cohérence des données (ex : jeux vidéo, calculs scientifiques).
- En mode d’alimentation “Haute performance”, Windows désactive le “core parking” (sommeil organisé des cœurs inactifs), amplifiant encore ce comportement : tous les cœurs restent actifs, les threads migrent encore plus.
Politique d’ordonnancement Linux
Depuis 2007, Linux utilise le CFS (Completely Fair Scheduler) comme ordonnanceur par défaut. Son objectif principal est d’assurer une répartition équitable du temps processeur tout en privilégiant la stabilité de l’affectation des threads. Concrètement, tant qu’aucune autre charge n’entre en concurrence, un thread reste exécuté sur le même cœur aussi longtemps que possible, ce qui maximise l’utilisation du cache et limite les transferts de données entre cœurs.
Le CFS repose sur un arbre rouge-noir pour gérer l’équité :
- Chaque processus accumule un temps virtuel (vruntime) proportionnel à son utilisation du processeur.
- Le processus avec le plus petit vruntime est toujours sélectionné en priorité.
- Ce mécanisme garantit une équité parfaite à long terme.
Le CFS est très efficace, avec une complexité de O(log n) pour les opérations d’insertion et de sélection. Il peut ainsi gérer des milliers de processus avec un overhead minimal. Référence : Documentation noyau Linux
De plus, le CFS tient compte de la topologie du processeur (cœurs physiques, SMT, sockets, CCX, etc.). En pratique :
- Un programme monothread reste généralement fixé sur le même cœur, sauf contrainte particulière.
- Les performances deviennent plus prévisibles, avec des coûts de migration réduits, ce qui améliore la réactivité et les performances globales.
- Cache hit rate plus élevé : ~15-20% d’amélioration sur les workloads intensifs
Conclusion
L’efficacité de l’ordonnanceur dépend de sa capacité à comprendre l’architecture matérielle et à minimiser les migrations de processus, surtout pour les applications à haute intensité de calcul ou très sensibles à la latence. Linux adopte généralement une approche plus efficace sur ce point que Windows, particulièrement sur des matériels modernes multi-cœurs et multi-processeur.