Abstract
La détection des plantes dans l'agriculture de précision est une tâche difficile et en général implique l'utilisation d'une segmentation par instances, elle même basée sur la détection des objets, suivie d'une segmentation sémantique sur chaque objet pour détecter leurs masques i.e les contours des objects. La partie détection d'objets utilise la régression par boîte englobante et la suppression du non-maximum (NMS) pour éliminer les prédictions en double. Lorsque deux objets se chevauchent avec un rapport important, l'un d'eux est supprimé et/ou fusionné. Cette approche des limitation dans le cas de scène dense en objects, en particulier en présence d'ombres et d'occlusions. Pour remédier à ce problème, cette étude basée sur les récents mécanismes de réseaux neuronaux convolutionnels (CNN) propose une segmentation d'instance au niveau du pixel pour détecter les feuilles dans un environnement de feuillage dense. En outre, un nouveau jeu de données multispectrales de 300 images de plantes de haricots est introduit. La vérité terrain est définie par des polygones étiquetés et peut être utilisée pour entraîner et quantifier les algorithmes de détection des feuilles et de classification des cultures et des herbes.
@article{VAYSSADE2022106797,
title = {Pixelwise instance segmentation of leaves in dense foliage},
journal = {Computers and Electronics in Agriculture},
volume = {195},
pages = {106797},
year = {2022},
issn = {0168-1699},
doi = {https://doi.org/10.1016/j.compag.2022.106797},
url = {https://www.sciencedirect.com/science/article/pii/S0168169922001144},
author = {Jehan-Antoine Vayssade and Gawain Jones and Christelle Gée and Jean-Noël Paoli},
}
Motivation
La détection d'objets basée sur la régression de la boîte englobante est une tâche difficile dans une scène dense. A la place, on peu imaginer une segmentation de feuilles comme un problème de segmentation binaire de frontières tel que proposé par Morris2018. L'idée principale est de détecter les bords nets des feuilles ou de suivre l'ombre projetée d'une feuille sur celle du dessous. On va ici développez ici trois éléments (1) une architecture CNN pour détecter et séparer les feuille, (2) un algorithme simple de bassin versant qui prend la sortie CNN et un masque de végétation pour affiner la segmentation et (3) une fonction de perte adapté.
Données et vérité terrain
Les données ont été acquises sur le site de l'INRAE à Montoldre (Allier, France, à 46°20'30.3 "N 3°26'03.6 "E) dans le cadre du Challenge ANR RoSE en 2019. L'objectif du Challenge est de comparer objectivement les solutions proposées par les participants. Dans ce contexte, le défi fournit aux participants un plan d'évaluation et un ensemble de parcelles expérimentales de plantes de haricot et de maïs. En outre, diverses adventices naturelles (achillée, amarante, géranium, plantago, ...) et semées (moutardes, chénopodes, mayweed et ray-grass) sont gérées pour comparer les performances.
A partir des parcelles expérimentales présentées, un ensemble d'images a été acquis avec la camera Airphen. C'est une caméra multi-spectrale à six bandes spectrales, centré sur 450/570/675/710/730/850 nm avec une largeur de 10 nm. Bref, cette caméra a largement été présenté avant. En raison de la conception de la caméra, les images spectrales ne sont pas alignées. Une méthode d'enregistrement basée sur des travaux antérieurs pour cette caméra a été utilisée. Après le recalage, toutes les bandes spectrales sont redimensionnées à 1200*800 px et concaténées par canal où chaque dimension fait référence à une bande spectrale.
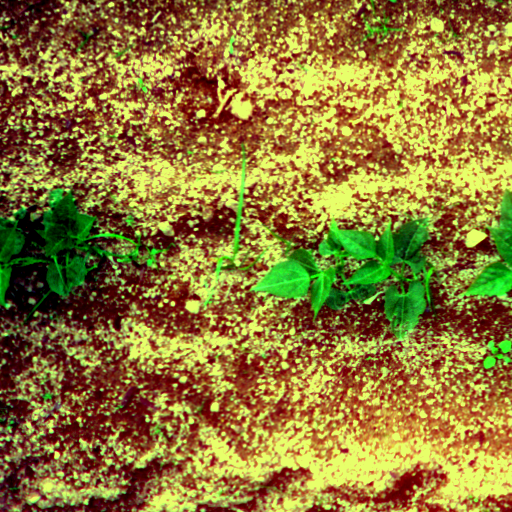
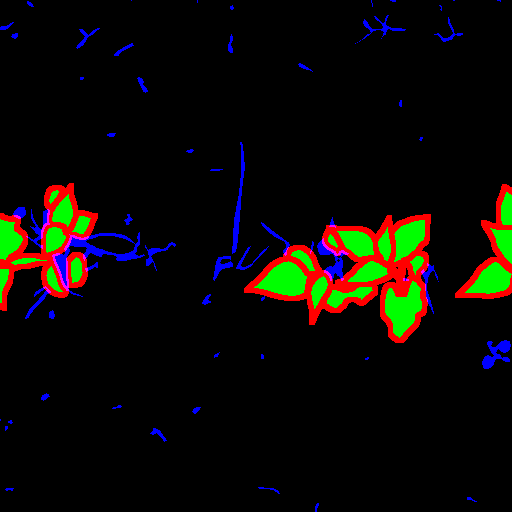
La vérité terrain est définie par des experts avec des polygones autour de chaque feuille. De plus, les polygones contiennent une étiquette pour leur classification entre culture et adventice (non utilisée dans cette étude). L'annotation a été définie à l'aide du logiciel d'annotation VIA et un total de 300 images de haricots ont été annotées, 170 en juin et 130 en octobre. Les données sont disponible ici https://entrepot.recherche.data.gouv.fr/. Étant donné que la méthode proposé repose sur une segmentation semantique, la vérité terrain a été transformé en masque de segmentation. Ainsi les polygones défini sont "dessiné dans une image. De plus, les polygones permettent de manipulé les zones d'incertitudes, l'épaisseur, ... etc. Dans cette étude, nous avons défini 4 classes, les petites feuilles (bleu), le contour des grande feuilles (rouge), l'intérieur des grandes feuilles (vert) et le background (noire) telque visible ci-dessous :
 |
|
Méthode
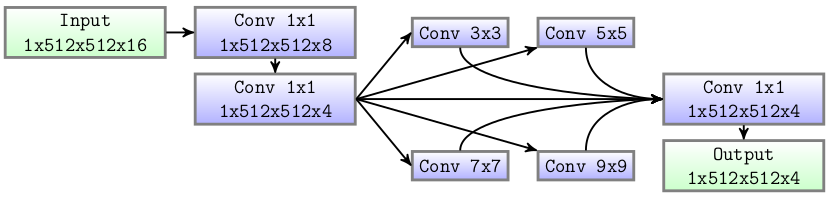
Contrairement aux architectures CNN récentes, l'approche proposée est légèrement plus décomposée comme les pipelines de vision informatique biomédicaux et agricoles standard Perez-Sanz-2017. Ainsi, l'architecture est composée de 3 modules amont (IIT, IBF, UFA) qui améliorent les données d'entrée et éliminent les informations inutiles, ces étapes ont été proposées dans un travail précédent pour reconstruire un indice de végétation. Ici, ces étapes sont utilisées pour apprendre des caractéristiques spectrales complexes sur les données d'entrée afin d'exploiter les relations inter-canaux. Après ces étapes, un core network est utilisé pour considérer les informations spatiales à différentes échelles sur l'image, le core network renvoie 4 cartes de caractéristiques réduites. Enfin, 3 modules en aval (CoordConv, UFA, Classification) sont placés à la fin du réseau pour bien mélanger les informations spectrales et spatiales. La fonction d'activation sigmoïde est utilisée à la fin de toutes les couches de convolution pour apprendre des structures plus complexes et permet la non-linéarité de la fonction reconstruite. La synthèse du réseau est visible ci-dessous :
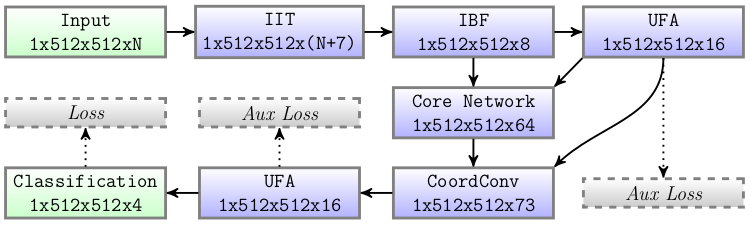 Synthèse de l'architecture CNN proposé
Synthèse de l'architecture CNN proposé
Entête du réseaux
La première ligne sur la figure ci-dessus montre l'amont du reseau, composé de 3 module. Ces étapes permettent e géré la variation de liminance, de remplacer les transformations colorimétriques des méthodes "standard" (indice de végétation par exemple) et de détecté certains gradients pertinent dans l'image, i.e les contours des feuilles.
Transformations initiales de l'image (IIT) Afin d'enrichir le pool d'informations, des transformations de bandes spectrales sont ajoutées pour prendre en compte les gradients spatiaux spécifiques de l'image et le mélange spectral. Le choix s'oriente vers sept transformations importantes à différents égards. L'écart-type entre les bandes spectrales, noté $\rho_{std}$ peut aider à détecter le mélange spectral. Par exemple, entre deux surfaces différentes comme le sol et les feuilles (qui ont une radiance spectrale opposée), le mélange spectral fait un pixel avec une combinaison linéaire, donc l'écart type tend vers zéro Louargant2017. Trois dérivées gaussiennes sur différentes orientations sont calculées. Les filtres Gxx, Gxy et Gyy sur $\rho_{std}$ donnent une information spatiale importante sur les ruptures de gradients, donc sur les limites extérieures des surfaces. Le Laplacien, les valeurs propres minimales et maximales (de la matrice Hessienne) aussi appelées ridge de la $\rho_{std}$ semblent détecter facilement les éléments fins LinVessel2015 tels que les monocotylédones pour les images de végétation. Toutes ces transformations sont concaténées à l'entrée de la bande spectrale normalisée par canal et construisent l'image d'entrée finale. Au total, nous avons six images spectrales plus sept transformations pour une image finale de 13 canaux.
Filtre de bande d'entrée (IBF) Pour supprimer les parties inutiles du signal, des filtres passe-bas, passe-haut et passe-bande sont ajoutés, car il n'est pas forcément nécessaire de conserver toutes les valeurs du signal. Pour appliquer le filtre passe-bas, nous utilisons l'équation $z = max(x-a,0)/(1-a)$ et permet ainsi de supprimer les valeurs faibles. Pour le filtre passe-haut, nous appliquons l'équation $w = max(b-x,0)/b$ pour supprimer les valeurs élevées. Le filtre passe-bande est le produit des filtres passe-bas et passe-haut $y = z*x$. La couche de sortie est la concaténation par canal des images d'entrée, du filtre passe-bas, du filtre passe-haut et du filtre passe-bande qui produisent 4*13 = 52 canaux. Enfin, pour réduire les données de sortie pour le reste du réseau, un goulot d'étranglement est inséré à l'aide d'une couche de convolution de 3$ \times 3$, et génère un nouveau tenseur avec 16 canaux.
Universal Function Approximator (UFA) Pour séparer efficacement les feuilles de l'arrière-plan et apprendre les caractéristiques spectrales, un Universal Function Approximator est défini en amont (Figure \ref{fig:ufa}). L'UFA est basé sur le théorème d'expansion de Taylor, une approche pour apprendre cette forme de développement est proposée par \citep{DenseNet} qui est communément appelé DenseNet et correspond alors à la somme de la concaténation du signal avec ces dérivés spatio-spectraux. Trois paramètres, tels que la $depth$ (nombre de convolutions), la $width$ (nombre de filtres noté $W$) et $k$ (taille du noyau) configurent le réseau et ont été fixés empiriquement à $depth=3$, $width=16$ et $k=1$. Une sortie auxiliaire est utilisée ici pour maximiser la similarité des classes en amont et extraire l'information spectrale pure.
 Universal Function Approximator
Universal Function Approximator
Cœur du réseaux
L'architecture CNN proposée est basée sur une architecture U-Net avancée appelée MFP-Unet (multi-feature pyramid U-net) proposée par moradi2019mfp. Il s'agit d'un réseau neuronal composé de plusieurs couches de convolution 2d entre différentes sous-échelles (comme une petite UFA). À chaque sous-échelle, la taille spatiale est divisée par deux et le nombre de filtres est multiplié par deux. Les sous-échelles sont obtenues par des couches de Max-Pooling, puis pour retrouver la taille originale, une couche d'UpSampling 2D est utilisée. L'architecture U-Net étant devenue très populaire, nous ne la présentons pas en détail. Dans cette étude, la profondeur du modèle U-Net est fixée à 3 down-scale (taille 512, 256, 128, 64). La spécificité de MFP-Unet est que toutes les cartes de caractéristiques de sous-échelle sont directement échantillonnées à la taille initiale, concaténées au canal et ensuite utilisées pour la classification (Figure ci-dessous). En outre, selon Morris2018, des fonctions de perte auxiliaires sont placées dans chaque couche de caractéristiques de sous-échelle et sont appliquées pour apprendre les bords à différentes échelles, rendant le réseau plus robuste à la résolution spatiale. Les pertes à chaque prédiction raccourcissent également le chemin de rétropropagation, ce qui permet une convergence plus rapide. Toutes les couches de convolution utilisent un noyau de $3\times3$ et sont suivies d'une normalisation par lots et d'une fonction d'activation sigmoïde.
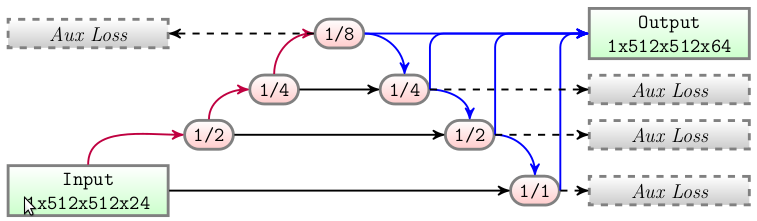
Le principe de UNET est de décomposé en plusieurs résolution puis d'intégré ces décomposition vers les résolutions plus hautes. Grosso-modo un "universal fonction approximator" avec intégration de différentes résolution. Pour MFP-UNET les couche basse de UNET sont en plus extraites directement, "ré-agrandit" vers la taille originel avec une convolution transposé :

Queu du réseaux
CoordConv Le modèle de réseau central produit une concaténation de 4 couches de 16 caractéristiques ($4 \times 512 \times 512 \times 16$) qui résulte en une couche de taille $1 \times 512 \times 512 \times 64$. Une couche de coordonnées est également concaténée et permet de considérer le mapping entre les coordonnées dans l'espace cartésien (x,y) vers l'espace pixel. Trois informations sont ainsi ajoutées, les coordonnées normalisées $x$ et $y$ et la coordonnée radiale $\sqrt{(x-.5)^2+(y-.5)^2}$. Ce module montre une amélioration et permet de supprimer le bruit, l'humidité du sol et de corriger quelques petits trous.
Universal Function Approximator (UFA) Cet UFA - également présenté en amont - est utilisé pour mélanger avec précision des caractéristiques provenant de différentes échelles ainsi que les coordonnées cartésiennes. Ce module reconstruit la fonction de mappage de l'espace cartésien vers une caractéristique spatio-spectrale de taille 1$ \times 512 \times 512 \times 16$. Cependant, contrairement à l'UFA amont, la taille du noyau $k$ a été fixée à $3$ pour prendre en compte le voisinage.
Classification et sortie auxiliaire La classification est effectuée par un petit réseau composé de deux couches de convolution $1\times1$. Suivi d'un ``Module de mise en commun pyramidale'' pour considérer les différentes échelles avant les sorties et lisser la prédiction des limites. Zhao2017 a montré que la fusion des caractéristiques de bas et haut niveau améliorait la tâche de segmentation. Elle consiste en la somme de différentes convolutions 2D dont la taille des noyaux a été fixée à 3, 5, 7 et 9. Le nombre de filtres est le même que le nombre de classes, soit 4$. Le résultat de chaque convolution est concaténé et l'image finale est donnée par une convolution 2D. De plus, toutes les convolutions sont suivies d'une normalisation par lots et d'une fonction d'activation sigmoïde. La figure ci-dessous montre ce petit réseau.
Fonction de perte
Une grande variété de fonctions de perte ont été développées pendant l'émergence de l'apprentissage profond. Récemment, Rahman2016 a proposé une solution pour optimiser une approximation de l'Intersection moyenne sur l'Union (mIoU) qui semble être la meilleure pour la segmentation binaire. La fonction de perte utilisant la vérité terrain ($p$) et la prédiction ($\hat{p}$) est définie par :
$ \texttt{mIoU}(p, \hat{p}) = 1 - \frac{p\hat{p}}{p+\hat{p} - p\hat{p}} $
Cette fonction de perte a été utilisée sur chaque auxiliaire. De plus, la perte est calculée séparément sur chaque classe, pondérée (notée $W_C$) et additionnée. Il en résulte la fonction :
$ \texttt{Aux}(p, \hat{p}) = \sum_{C=0}^{4} W_C \times \texttt{mIoU}(p_C, \hat{p}_C) $
Dans l'équation ci-dessus, les poids $W$ ont été empiriquement fixés à $[0.263, 0.790, 0.132, 0.079]$. Cela signifie que la deuxième classe (bords intérieurs) est prioritaire (pour séparer l'instance intérieure). Ensuite, ce sont les bords extérieurs qui permettent de séparer les "grandes" feuilles en petites et fines feuilles. Enfin, ce sont les feuilles fines (principalement le mélange spectral) et les grandes feuilles intérieures (essentiellement la végétation moins les limites) qui devraient être plus faciles à apprendre.
Dans les architectures CNN récentes pour la segmentation d'instances, la fonction de perte ne prend pas en compte le nombre d'instances détectées ou la forme de la segmentation. Cet aspect n'est évalué qu'après l'apprentissage, par exemple, en utilisant une métrique Symetric Best Dice. Ceci implique que nous ne pouvons pas garantir que le réseau est bien appris sur une scène dense, où les instances sont généralement fusionnées. Un problème est que jusqu'à récemment, les instances ne pouvaient pas être récupérées directement pendant l'apprentissage. Cela est dû à l'algorithme de "suppression non maximale" nécessaire après le CNN ou au temps nécessaire à l'association entre les instances détectées et la vérité terrain. Dans cet article, nous introduisons une nouvelle fonction de perte considérée en aval du réseau. L'idée principale est de prendre en compte une approximation de la qualité de la segmentation de chaque feuille. Pour ce faire, un histogramme trié du nombre de pixels associés à chaque composant connecté est calculé. Cela permet d'estimer rapidement les objets non détectés, sur-segmentés et fusionnés (figure ci-dessous).
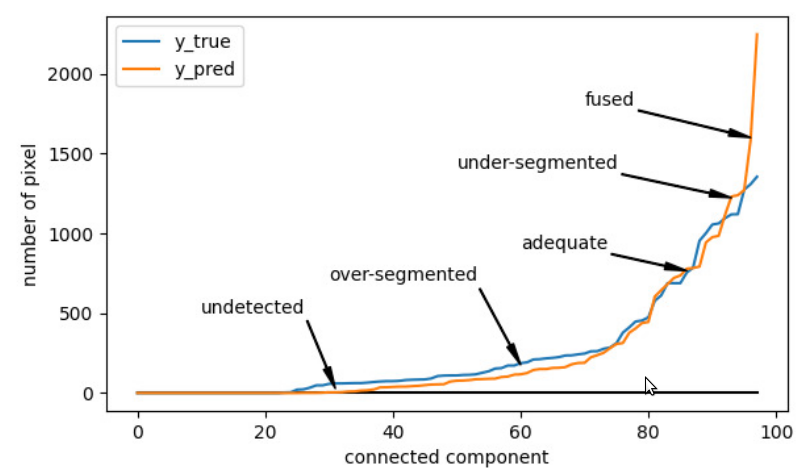
A partir de cet histogram, un pourcentage d'erreur absolu personnalisé a été défini :
- $$\texttt{Feuilles}(p, \hat{p}) = \frac{\sum_{i=0}^{N} |\texttt{leaky_relu}(cc_i(p)-cc_i(\hat{p}))| }{cc_{max}(p)+1}$$
- $$\texttt{leaky_relu}(x) = \begin{cases} \mbox{$x$} & \mbox{if } x >= 0\\ \mbox{$x*0.2$} & \mbox{if } x < 0 \end{cases} $$
Dans l'équation ci-dessus, $N$ est le nombre de composantes, $cc_i(p)$ et $cc_i(\hat{p})$ sont respectivement le nombre de pixels d'une composante connectée dans la vérité terrain et sur la segmentation prédite dans l'histogramme trié. Alors que $cc_{max}(p)$ est le nombre maximum de pixels d'une composante dans la vérité terrain. Le leaky_relu a été utilisé pour donner explicitement la priorité à l'apprentissage sur la sous-segmentation plutôt que sur la sur-segmentation, ce qui permet de travailler d'abord sur les objets fusionnés. Ceci a été défini parce que les fonctions de pertes conventionnelles ne donnaient pas de bons résultats dans une couverture végétale dense, entraînant la segmentation et la détection d'une large zone comme une seule entité. Pour autant que nous le sachions, c'est la première étude qui propose ce type de perte.
Watershed
L'architecture U-Net utilisée est bonne pour la détection des "gros" éléments dans une scène, mais souffre d'un manque de précision sur les éléments très petits et fins. D'un autre coté, dans un travail antérieur, le meilleur masque de segmentation sol/végétation a déjà été proposé, ce travail montre de meilleures performances que l'ajout d'une classe spécifique sur le réseau. Ainsi, notre travail précédent a été utilisé ici pour obtenir le meilleur masque de segmentation sol/végétation comme entrée d'un algorithme de watershed. Il a également été appris sur des données spécifiques qui ont plus de conditions d'illumination et devraient être plus robustes, en particulier pour les éléments fins.
Le réseau proposé génère 4 classes. Les deux premières sont associées aux limites des "grandes" feuilles (notées $Edges=Outer+Inner$). La troisième est celle des feuilles petites et fines (notée $Thin$), et la quatrième est celle de l'intérieur des grandes feuilles notée $Big$. Le watershed est également initialiser avec des "Seed" qui ont été définie avec l'équation suivante pour générer le masque de la graine : $Seed = Thin + Big - Edges$
Exemples
sortie brute du réseaux
 |
 |
 |
Toutes les étapes aplliqué à une grande image
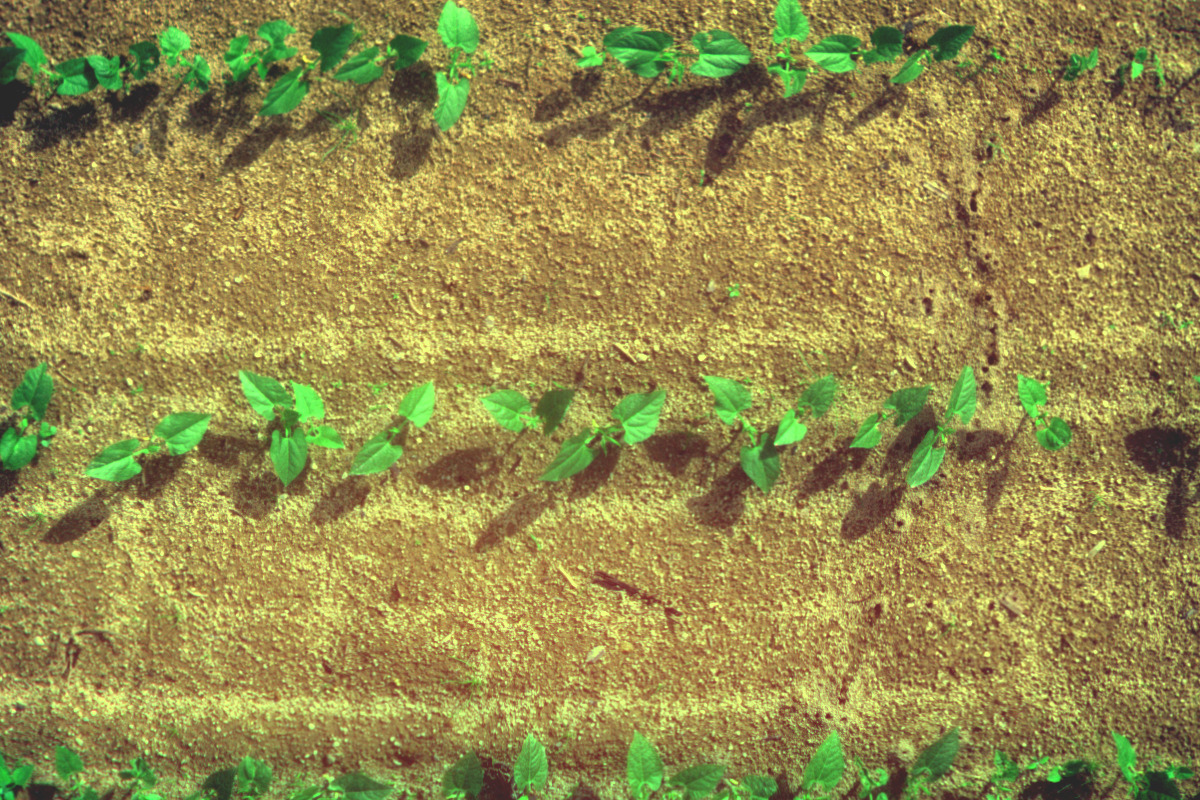 fausse couleurs
fausse couleurs masque sol/végétation
masque sol/végétation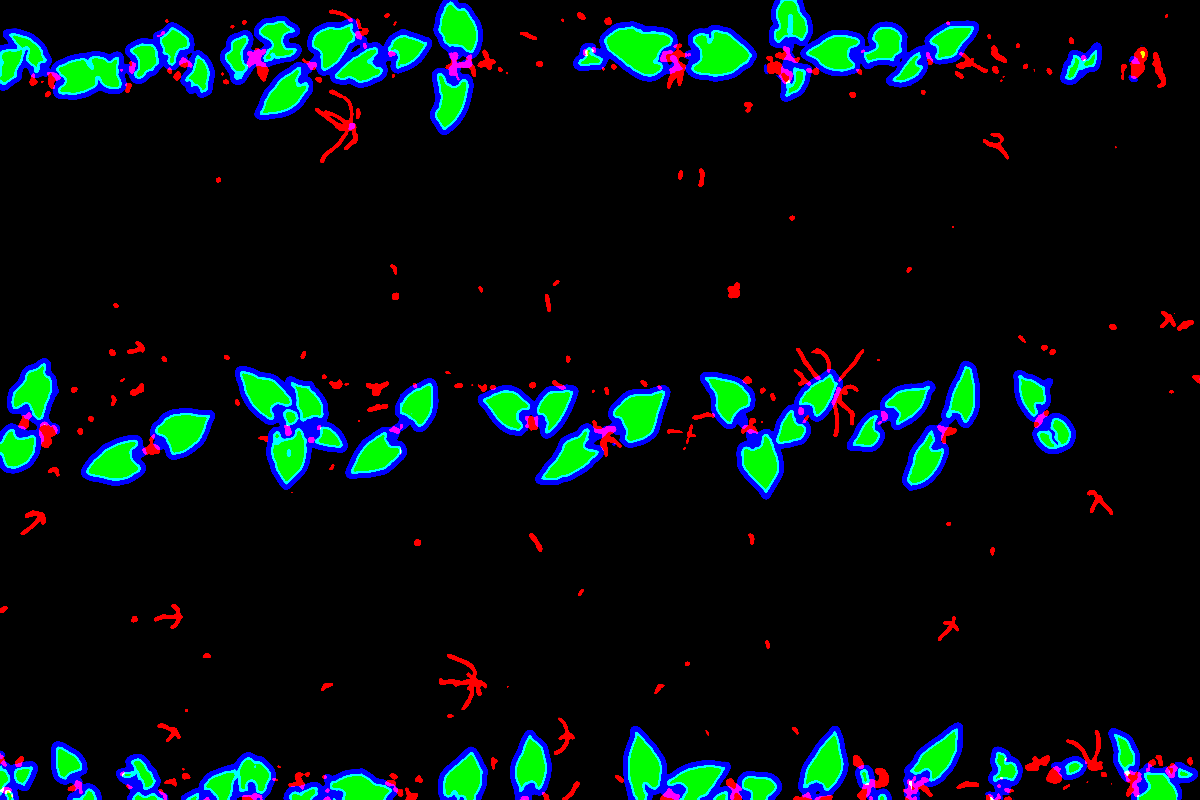 detection mfp-unet
detection mfp-unet Sans opérateurs morphologiques
Sans opérateurs morphologiques Avec opérateurs morphologiques
Avec opérateurs morphologiques
Classification
A titre d'illustration, dans le cadre du challenge RoSE, l'idée est de séparer les cultures des advantices pour appliqué un traitement différencié. Grace à la segmentation, de nombreuses propriétés peuvent être extractes sur chaques feuilles permettant de crée un modèle de classification culture/advantice. Ces travaux seront décris plus tard. Ci-dessous, deux modèles permettent la discrimination dans des lignes de maïs, puis des lignes de haricot. Le taux de discrimination avoisine les 91.2%
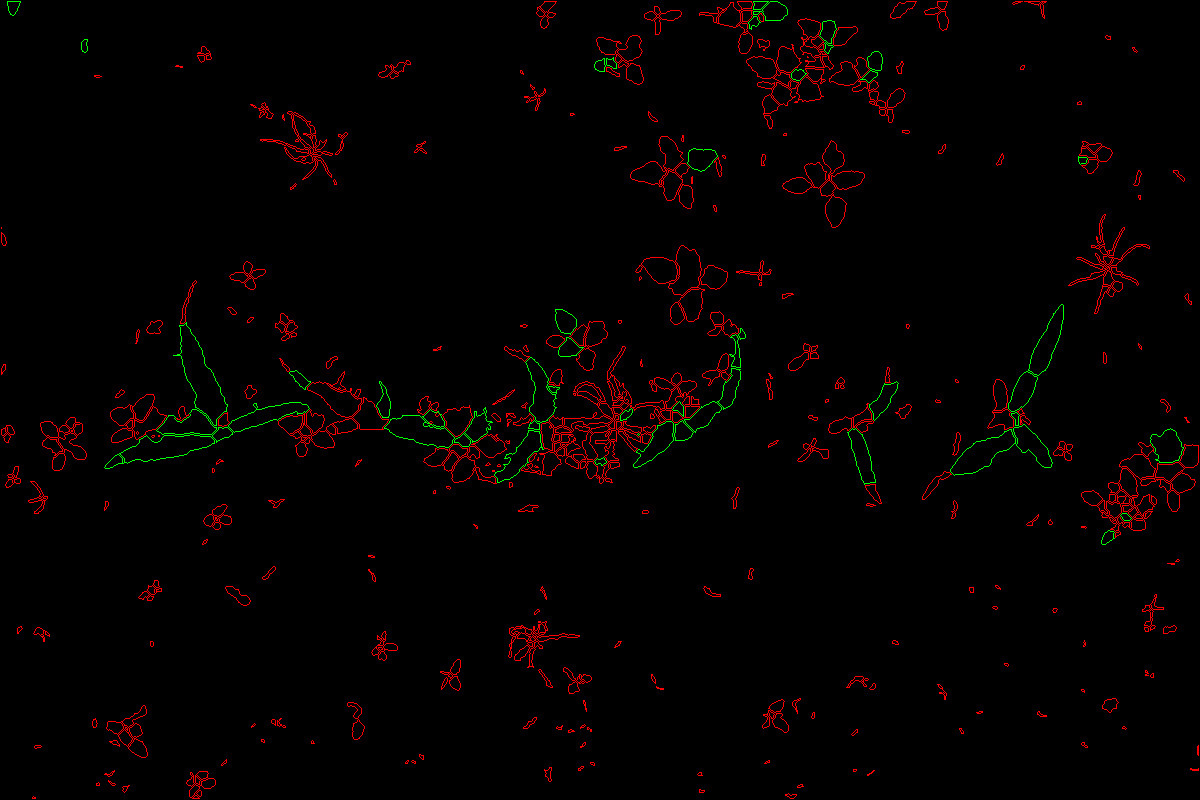 Classification Mais
Classification Mais Classification Haricot
Classification Haricot