Problème
L’éclairage – direct ou indirect – par des sources nombreuses est toujours problématiques en temps réel, car il induit une surcharge de la bande passante et (souvent) du calcul. Plusieurs techniques existent pour réduire les calculs, dont, notamment, le calcul des lumières uniquement en les zones qu’elles éclairent. Ceci peut être effectué en espace image (tiled rendering) ou en espace scène (clustered rendering). Le tiled rendering fait cependant un clustering plus approximatif des sources, et des cas particuliers existent où la technique devient non-bénéfique (dans des configurations où la profondeur varie trop sur une même tuile pour permettre de sélectionner efficacement les lumières affectantes).
Cette article propose une implémentation de l'article Clustered Deferred and Forward Shading, Olsson, Billeter, et Assarsson, 2012
Choix de la technique

Nous nous intéresserons donc au clustered shading ; la technique présentée dans Clustered Deferred and Forward Shading, Olsson, Billeter, et Assarsson, 2012 présente en effet quelques avantages sur le tiled rendering. La segmentation est, de par sa nature 3D, mieux adaptée, et permet d’éviter les variations de performance liées aux changements de vue. Les auteurs précisent que les pires cas sont également mieux gérés. La technique permet également de prendre d’autres paramètres de la scène en compte lors pour l’éligibilité des lumières, et en particulier les normales. Le nombre de lumières supporté annoncé sur papier est estimé à 1,000,000 de sources (ponctuelles). La gestion des ombres n’est, en revanche, pas plus prise en charge qu’avec du tiled rendering, dans le cadre many-lights.
Clustering
Pour la réalisation du many-light, plusieurs étapes de calcul ont été développées afin d’optimiser la répartition des données au sein des grilles de calculs parallèles, évidement en essayent au mieux de minimiser les caches miss et d’obtenir des programmes avec le moins de branche miss possibles. Dans cette optique, un premier programme établit un filtrage avec un test de frustum sur toutes les Lights, cela permet de créer un premier filtrage hautement parallèle sur toutes les lights, pour exclure toutes les lumières qui n’appartiennent pas à la grille de cluster et donc supprimer un test à l’étape suivante. C’est le rôle du premier compute shader. L’étape suivante consiste donc à itérer sur toutes les lumières visibles dans le frustum. Ce dernier étant découpé dans une grille en 3 dimensions dont la taille est restreinte par le matériel et donnée lors de l’instanciation. Chaque lumière est répartie dans la grille en fonction de sa position, cela permet de diminuer drastiquement le nombre de lumières à prendre en compte lors du shading.
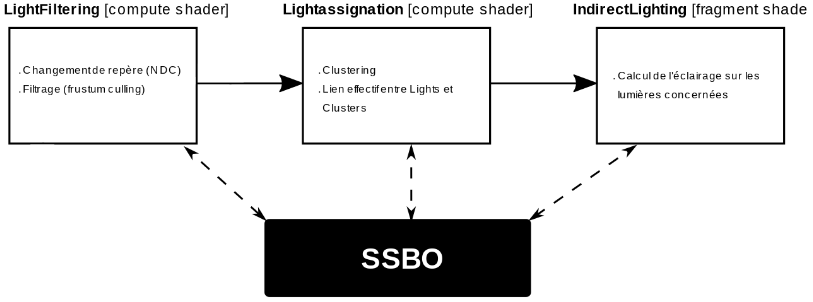
Étapes de calcul de l’éclairage many-lights. Les deux premières constituent la phase de clustering, encompute shaders. La dernière représente le calcul de l’éclairage. Le SSBO mentionné est celui appelég_buffer(oug_texture) et qui contient les sources lumineuses. Il y en a plusieurs autres, cruciaux également
Critère de clustering L’un des critères les plus directs est la position. Elle sera considérée dans l’espace Camera. Le plus naturel serait de subdiviser le frustum uniformément, mais on obtiendrait des clusters très inégaux. Pour pallier à ce problème, on considère le logarithme de ces positions, ce qui offre des clusters répartis de manière plus égale. Il est également possible d’utiliser d’autres critères pour les clusters. Olsson, Billeter, et Assarsson proposent un clustering tenant compte de la normale d’un fragment, ce qui permet de potentiellement réduire encore le nombre de lumières affectant un même fragment. Le cas limite suivant doit être évité : il peut tout à fait arriver qu’un fragment soit affecté par toutes les lumières, si elles sont toutes concentrées en un point. Ce cas sera évité en instaurant une limite au nombre de sources affectant simultanément un point. Nous pensons à une limite située entre 128 et 1024 sources. Ce cas devrait arriver très peu en pratique, malgré tout, mais nous permet d’optimiser notre calcul.
Stockage et structure de données Pour chaque cluster il faut stocker, d’une manière ou d’une autre, les sources qu’il contient. Cette question est difficile à résoudre, notamment car elle demande de faire un compromis entre la latence induite par des indirections dans le cas d’une représentation indexée et la difficulté que constitue la recopie et le transfert des données sur GPU dans le cas d’une duplication. Après discussion, nous sommes arrivés à la conclusion que le système de cache du GPU amortirait probablement très bien la latence liée au déréférencement alors que la recopie des sources poserait de gros problèmes de bande passante pour un gain par rapport au déréférencement minime. Une représentation possible consiste à créer un index des lumières par cluster et à les regrouper dans une liste, de manière semblable à ce qui est fait en tiled shading dans Real-time Many-light Management and Shadows with Clustered Shading p.62.